我在之前已经写过一篇文章详细介绍了SpringMVC,这是Java生态做web开发最广泛的开发框架。但是它在许多场景下越来越力不从心了,这是从servlet标准之上带出来的问题,在处理比如sse、高并发场景下显得十分繁琐。
如果你希望做一个高并发高吞吐的Java服务,那么webflux几乎是你的必然选择。如果你在写一个类似ChatGPT的聊天服务,或者在写一个非一请求一响应的web应用,使用webflux是一个更好的选择。本文将详细介绍WebFlux的应用与原理。
注意: 并不是说spring mvc就无法实现这些场景的功能,只是这些场景在spring mvc这套框架下实现起来不怎么优雅。
本文与 解决方案——异步操作 、 SpringMVC的朴素解释 和 Netty的朴素解释 有关联。可先查看相关文章后再回来阅读本文。
一个示例
这里我以一个大模型中转服务作为一个示例来详细介绍spring webflux如何使用。
假设你正在开发一个类似openai的chat一样的接口,接口需要你通过调用方传递过来的stream字段来决定只一次性返回所有数据,还是将数据一点点返回。在使用springmvc的情况下,你可以如此实现:
package org.example.web;
import lombok.Builder;
import lombok.Data;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@RestController
@RequestMapping("test")
public class TestController {
private final ExecutorService executor = Executors.newSingleThreadExecutor();
@PostMapping("chat")
public Object chat(@RequestBody ChatBody body){
if(body.stream){
SseEmitter emitter = new SseEmitter();
String[] data = "hello world!!!".split("");
executor.execute(()->{
try {
for (String datum : data) {
ChatRespChunkBody sseData = ChatRespChunkBody.builder().chunk(datum).build();
emitter.send(SseEmitter.event().data(sseData));
Thread.sleep(500);
}
// 发送 [done] emitter.complete();
} catch (Exception e) {
emitter.completeWithError(e);
}
});
return emitter;
}else {
ChatRespBody respBody = ChatRespBody.builder().message("hello world!!!").build();
return respBody;
}
}
@Data
public static class ChatBody{
private boolean stream;
}
@Data
@Builder public static class ChatRespBody{
private String message;
}
@Data
@Builder public static class ChatRespChunkBody{
private String chunk;
}
}此示例也可以作为异步操作的一个补充。 可以看到要返回sse只需要返回SseEmitter对象即可,数据发送部分通过异步的另一个线程调用SseEmitter对象的发送函数就行。
那么对于webflux,要做到一样的效果通常要更简单优雅,下面是代码:
package org.example.webflux;
import lombok.Builder;
import lombok.Data;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
@RestController
@RequestMapping("test")
public class TestController {
@PostMapping("chat")
public ResponseEntity<?> chat(@RequestBody ChatBody body){
if (body.stream) {
// 或者使用ServerSentEvent.builder(d).build()就行更加细化控制
// ServerSentEvent.builder().event().data().id().comment().build()
List<ChatRespChunkBody> list = Arrays.stream("hello world!!!".split("")).map(d -> ChatRespChunkBody.builder().chunk(d).build()).collect(Collectors.toList());
Flux<ChatRespChunkBody> elements = Flux.fromIterable(list).delayElements(Duration.ofMillis(500));
return ResponseEntity.ok()
.contentType(MediaType.TEXT_EVENT_STREAM)
.body(elements);
}else {
return ResponseEntity.ok(ChatRespBody.builder().message("hello world!!!").build());
}
}
@Data
public static class ChatBody{
private boolean stream;
}
@Data
@Builder public static class ChatRespBody{
private String message;
}
@Data
@Builder public static class ChatRespChunkBody{
private String chunk;
}
}想要实现相同的效果,webflux要简洁很多,因为Flux对象本身就代表一个数据流。同理我们也可以返回ServerSentEvent对象对返回数据进行更加精细化的设置,比如设置id和event。
响应式服务
整个webflux是基于reactor-netty封装实现的web框架, 而reactor-netty是Reactor对netty的封装,且reactor又是对reactive-streams的实现,reactive-streams又是对响应式宣言的实践。
reactive streams
整个reactive-streams包十分简单,就以下四个接口:
// 数据发布
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
// 订阅消费
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
// 订阅关系
public interface Subscription {
public void request(long n);
public void cancel();
}
// 管道
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}可以看到,这四个接口非常简单,各个部分组合起来形成一个全异步的双向管道:消费端(Subscriber)订阅(subscribe)生产Publisher管道。生产管道内部构建订阅关系(Subscription)并触发回调(onSubscribe)将订阅关系告诉Subscriber端。消费端通过订阅关系Subscription向生产端请求(request)所需量的资源。生产端收到请求后将酌情通过回调将资源(onNext)、完成信息(onComplete)、或者错误信息(onError)给到消费端。此过程中消费端可以取消(cancel)订阅关系来中止生产端工作。
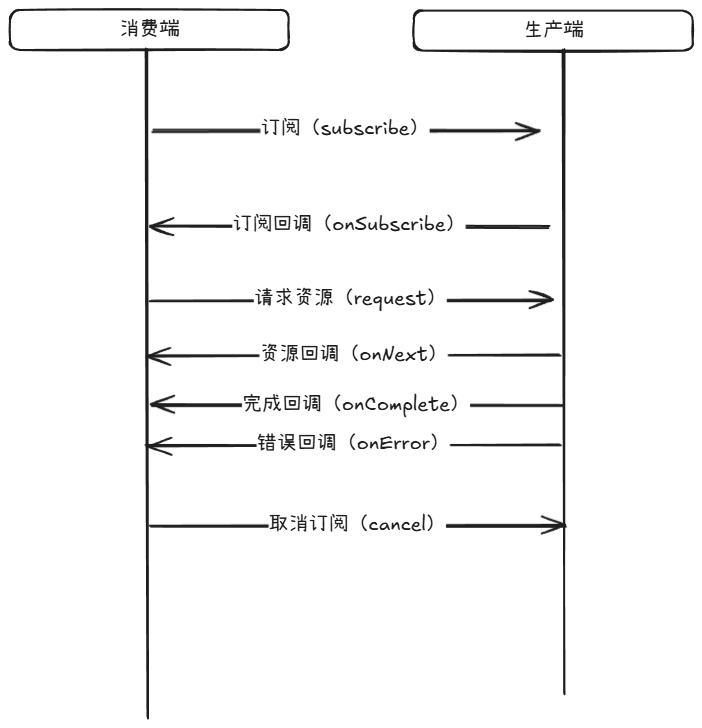
这和诸多网络协议有相似之处。从订阅到订阅回调其实可以看做一个握手过程,从请求资源到完成资源发送可以看作数据传输过程,取消订阅是挥手过程。
我们可以看到消费端的消费能力可以通过request传递给生产端,这使得整个管道很容易就能实现背压。我们也可以看到,整个管道的流动触发是subscribe操作,也就是说,在触发订阅之前,生产端的一切业务都不会被触发(这点得看实现,不过在绝大多数响应式系统之中都是订阅之后才会有业务流动的)。我们更加可以清楚的看到生产端与消费端的沟通都是通过回调来实现的,这使得解耦非常简单,且每个环节我们都可以做成异步的,但是这与简单的事件回调又有所不同,通过标准接口实现,管道的各个环节组合起来可以实现复杂的业务逻辑,这使得我们不会陷入到回调地狱之中。在下文会讲到reactor如何实现的。
reactive-streams整个包的作用实际上就是定义规范用的,这个和javax系列的包是异曲同工之妙的,不负责实现,只负责定义,比如经典的javax.servlet (现在应该是 jakarta.servlet )就是对传统servlet web开发的标准定义,而其具体实现是由tomcat之类的servlet容器来实现的。
java官方在很长时间都是处于这样定义标准然后由厂商实现标准的状态,后来在jdk8停滞了非常漫长的一段时间,而计算机世界发展迅速,很显然java标准已经逐渐跟不上潮流了,但是在jdk 9,java还是将reactive streams纳入到了Java标准里面,如下,和上面的接口一模一样:
package java.util.concurrent;
public final class Flow {
private Flow() {}
@FunctionalInterface
public static interface Publisher<T> {
public void subscribe(Subscriber<? super T> subscriber);
}
public static interface Subscriber<T> {
public void onSubscribe(Subscription subscription);
public void onNext(T item);
public void onError(Throwable throwable);
public void onComplete();
}
public static interface Subscription {
public void request(long n);
public void cancel();
}
public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> {
}
static final int DEFAULT_BUFFER_SIZE = 256;
public static int defaultBufferSize() {
return DEFAULT_BUFFER_SIZE;
}
}但是很遗憾的是,目前市面上的实现还没有完成适配,目前还在过度阶段。reactive streams倒是有一个适配器工具FlowAdapters用来可以将两个对象相互装饰转换。这个技巧其实也贯穿了整个reactor的实现。
reactor
前文有讲到 reactor 是对reactive streams的实现。在Android开发领域,有另一个非常著名的实现—— RxJava ——客户端应用非常契合这种响应式编程,且应用十分广泛。
前文示例我们已经提到了Flux代表一个数据流对象,他是reactor core提供的一个抽象类,它实现了Publisher接口,这个Publisher是reactive stream的一部分。reactor除了提供Flux还提供了Mono,Mono代表一个元素结果。理念上类似Future,不过作为Publisher,它只能给消费端生产0到1个数据。
Flux和Mono都提供了大量的工厂类来获得我们想要的Flux或者Mono对象,或者互相转换,或者实现逻辑,如下是一个简单的示例:
public class ReactorTest {
public static void main(String[] args) {
Integer[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
Flux.fromArray(arr).map(Object::toString).take(10).subscribe(System.out::println);
}
}这段逻辑非常简单,如果你熟悉java stream api的话,你可能会觉得看起来好像有点似曾相识,是的,reactor在实现上使用了大量的函数式接口,运用了函数式编程理念。我们知道lambda表达式的本质在Java中是一个匿名类对象,那 map(Object::toString).take(10) 本质是对该对象进行装饰增强,为了避免出现回调地狱,响应式编程内部对逻辑进行了大量的封装。我们以map方法为例:
public final <V> Flux<V> map(Function<? super T, ? extends V> mapper) {
if (this instanceof Fuseable) {
return onAssembly(new FluxMapFuseable<>(this, mapper));
}
return onAssembly(new FluxMap<>(this, mapper));
}可以看到调用map之后创建了新的FluxMap或者FluxMapFuseable对象来处理,并且类型从T变成了V。我们接着看FluxMap对象:
final class FluxMap<T, R> extends InternalFluxOperator<T, R> {
final Function<? super T, ? extends R> mapper;
FluxMap(Flux<? extends T> source,
Function<? super T, ? extends R> mapper) {
super(source);
this.mapper = Objects.requireNonNull(mapper, "mapper");
}
@Override
@SuppressWarnings("unchecked")
public CoreSubscriber<? super T> subscribeOrReturn(CoreSubscriber<? super R> actual) {
if (actual instanceof Fuseable.ConditionalSubscriber) {
Fuseable.ConditionalSubscriber<? super R> cs =
(Fuseable.ConditionalSubscriber<? super R>) actual;
return new MapConditionalSubscriber<>(cs, mapper);
}
return new MapSubscriber<>(actual, mapper);
}
static final class MapSubscriber<T, R>
implements InnerOperator<T, R> {
// Subscription 与 Subscriber 接口实现
}
static final class MapConditionalSubscriber<T, R>
implements Fuseable.ConditionalSubscriber<T>, InnerOperator<T, R> {
// Subscription 与 Subscriber 接口实现
}
}可以看到这个我们的Lambda通过装饰者模式得到了转换增强,注意三个地方,InternalFluxOperator类、InnerOperator接口和subscribeOrReturn方法。其中InternalFluxOperator类继承关系如下:
InternalFluxOperator 继承 FluxOperator 并实现 OptimizableOperator
FluxOperator 继承 Flux 实现 CorePublisher(Publisher)
OptimizableOperator 继承 CorePublisher(Publisher)并提供了下面的方法:
CoreSubscriber<? super OUT> subscribeOrReturn(CoreSubscriber<? super IN> actual) throws Throwable;也就是说FluxMap的本质还是一个Publisher,同理FluxMapFuseable也是一个Publisher。而InnerOperator接口是CoreSubscriber(Subscriber)和Subscription的组合,具备Subscriber和Subscription的能力。
我们可以看到reactor并未直接使用Subscriber和Publisher而是使用自己继承增强后的CoreSubscriber和CorePublisher。而所有的Flux相关的操作都是继承自InternalFluxOperator抽象类(它的位置类似FilterInputStream或者FilterOutputStream)。而subscribeOrReturn方法正是由此类调用的:
abstract class InternalFluxOperator<I, O> extends FluxOperator<I, O> implements Scannable,OptimizableOperator<O, I> {
@Nullable
final OptimizableOperator<?, I> optimizableOperator;
protected InternalFluxOperator(Flux<? extends I> source) {
super(source);
if (source instanceof OptimizableOperator) {
@SuppressWarnings("unchecked")
OptimizableOperator<?, I> optimSource = (OptimizableOperator<?, I>) source;
this.optimizableOperator = optimSource;
}
else {
this.optimizableOperator = null;
}
}
@Override
@SuppressWarnings("unchecked")
public final void subscribe(CoreSubscriber<? super O> subscriber) {
OptimizableOperator operator = this;
try {
while (true) {
// 在subscribe的时候调用subscribeOrReturn
subscriber = operator.subscribeOrReturn(subscriber);
if (subscriber == null) {
// null means "I will subscribe myself", returning...
return;
}
// 调用下一个
OptimizableOperator newSource = operator.nextOptimizableSource();
if (newSource == null) {
operator.source().subscribe(subscriber);
return; }
operator = newSource;
}
}
catch (Throwable e) {
Operators.reportThrowInSubscribe(subscriber, e);
return; }
}
@Nullable
public abstract CoreSubscriber<? super I> subscribeOrReturn(CoreSubscriber<? super O> actual) throws Throwable;
}这就吧所有的Publisher串联起来了,每一个Publisher都会在subscribe都会先调用subscribeOrReturn获得增强后的Subscriber,然后调用源头的subscribe向源头传导订阅。最终到达FluxArray对象,会调用Subscriber的onSubscribe方法:
final class FluxArray<T> extends Flux<T> implements Fuseable, SourceProducer<T> {
final T[] array;
@SafeVarargs
public FluxArray(T... array) {
this.array = Objects.requireNonNull(array, "array");
}
@SuppressWarnings("unchecked")
public static <T> void subscribe(CoreSubscriber<? super T> s, T[] array) {
if (array.length == 0) {
Operators.complete(s);
return; }
// 调用onSubscribe
if (s instanceof ConditionalSubscriber) {
s.onSubscribe(new ArrayConditionalSubscription<>((ConditionalSubscriber<? super T>) s, array));
}
else {
s.onSubscribe(new ArraySubscription<>(s, array));
}
}
@Override
public void subscribe(CoreSubscriber<? super T> actual) {
subscribe(actual, array);
}
...
}而前文我们已经看到,map方法装饰的时候通过 subscribeOrReturn 给到的是一个MapSubscriber对象,它的onSubscribe如下:
@Override
public void onSubscribe(Subscription s) {
if (Operators.validate(this.s, s)) {
this.s = s;
actual.onSubscribe(this);
}
}这里就只是做了向下游传导。最终会传导到LambdaSubscriber对象,其实现如下,非常简单调用了 s.request(Long.MAX_VALUE)
@Override
public final void onSubscribe(Subscription s) {
if (Operators.validate(subscription, s)) {
this.subscription = s;
if (subscriptionConsumer != null) {
try {
subscriptionConsumer.accept(s);
}
catch (Throwable t) {
Exceptions.throwIfFatal(t);
s.cancel();
onError(t);
}
}
else {
s.request(Long.MAX_VALUE);
}
}
}而MapSubscriber对象依然是向上传导:
@Override
public void request(long n) {
s.request(n);
}最终到达ArraySubscription就会调用s.onNext(t) 、s.onComplete() 和 s.onError(e) :
@Override
public void request(long n) {
if (Operators.validate(n)) {
if (Operators.addCap(REQUESTED, this, n) == 0) {
if (n == Long.MAX_VALUE) {
fastPath();
}
else {
slowPath(n);
}
}
}
}
void slowPath(long n) {
final T[] a = array;
final int len = a.length;
final Subscriber<? super T> s = actual;
int i = index;
int e = 0;
for (; ; ) {
if (cancelled) {
return;
}
while (i != len && e != n) {
T t = a[i];
if (t == null) {
s.onError(new NullPointerException("The " + i + "th array element was null"));
return; }
if (cancelled) {
return;
}
i++;
e++;
}
if (i == len) {
s.onComplete();
return; }
n = requested;
if (n == e) {
index = i;
n = REQUESTED.addAndGet(this, -e);
if (n == 0) {
return;
}
e = 0;
}
}
}
void fastPath() {
final T[] a = array;
final int len = a.length;
final Subscriber<? super T> s = actual;
for (int i = index; i != len; i++) {
if (cancelled) {
return;
}
T t = a[i];
if (t == null) {
s.onError(new NullPointerException("The " + i + "th array element was null"));
return; }
s.onNext(t);
}
if (cancelled) {
return;
}
s.onComplete();
}对于map装饰,此时需要应用mapper做映射:
@Override
public void onNext(T t) {
if (done) {
Operators.onNextDropped(t, actual.currentContext());
return; }
R v;
try {
// 映射
v = Objects.requireNonNull(mapper.apply(t),
"The mapper returned a null value.");
}
catch (Throwable e) {
Throwable e_ = Operators.onNextError(t, e, actual.currentContext(), s);
if (e_ != null) {
onError(e_);
}
else {
s.request(1);
}
return;
}
actual.onNext(v);
}而对于take装饰,在没有余量的时候,需要向上游取消获取数据,向下调用完成回调:
@Override
public void onNext(T t) {
if (done) {
Operators.onNextDropped(t, actual.currentContext());
return; }
long r = remaining;
if (r == 0) {
s.cancel();
onComplete();
return; }
remaining = --r;
boolean stop = r == 0L;
actual.onNext(t);
if (stop) {
s.cancel();
onComplete();
}
}最下游的LambdaSubscriber则直接消费就行:
@Override
public final void onNext(T x) {
try {
if (consumer != null) {
consumer.accept(x);
}
}
catch (Throwable t) {
Exceptions.throwIfFatal(t);
this.subscription.cancel();
onError(t);
}
}可以看到,整个流程是非常清晰的,重点在于在subscribe订阅之前是如何使用装饰者模式增强对象完善整个业务流程的。
得益于回调与背压的设计基础,这使得各个环节可以运行在不同的调度器(线程池)下面,这是一个巨大的优势,传统的servlet服务器的请求是与线程相绑定的,所以我们可以使用如下方式获得request:
// 其实是获得ThreadLocal绑定的ServletRequestAttributes,而这里面存有Request
((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();虽然很方便,但是这也意味着我们的服务无法承载高并发高吞吐的情况,毕竟线程资源是昂贵且有限的。而Reactor设计了Scheduler调度器,我们可以在任意阶段使用任意的调度器来讲将时操作分离,使得当前线程可以空闲下来处理其他工作。示例如下:
public static void main(String[] args) {
Integer[] arr = {1, 2, 3};
Flux.fromArray(arr)
.map(Object::toString)
.doOnNext(d->{
log.info("subscribeOn、publishOn、cancelOn之前----doOnNext");
})
.publishOn(Schedulers.newParallel("publishOn"))
.doOnSubscribe(subscription->{
log.info("subscribeOn、cancelOn之前,publishOn之后----doOnSubscribe");
})
.doOnRequest(i->{
log.info("subscribeOn、cancelOn之前,publishOn之后---- doOnRequest {}",i);
})
.doOnCancel(()->{
log.info("subscribeOn、cancelOn之前,publishOn之后---- doOnCancel");
})
.cancelOn(Schedulers.newParallel("cancelOn"))
.take(2)
.doOnSubscribe(subscription->{
log.info("subscribeOn之前,cancelOn publishOn之后----doOnSubscribe");
})
.doOnRequest(i->{
log.info("subscribeOn之前,cancelOn publishOn之后----doOnRequest {}",i);
})
.doOnCancel(()->{
log.info("subscribeOn之前, cancelOn publishOn之后---- doOnCancel");
})
.doOnNext(d->{
log.info("subscribeOn之前, cancelOn publishOn之后 ----doOnNext");
})
.take(1)
.subscribeOn(Schedulers.newParallel("subscribeOn"))
.doOnSubscribe(subscription->{
log.info("subscribeOn、publishOn、cancelOn之后 ---- doOnSubscribe");
})
.doOnRequest(i->{
log.info("subscribeOn、publishOn、cancelOn之后---- doOnRequest {}",i);
})
.doOnNext(d->{
log.info("subscribeOn、publishOn、cancelOn之后 ----doOnNext");
})
.subscribe(d->{
log.info("subscribeOn、publishOn、cancelOn之后---- subscribe");
});
}我们先从最简单的cancelOn开始分析,和其他工厂方法一样,它依然是使用装饰者对当前Publisher进行增强的:
public final Flux<T> cancelOn(Scheduler scheduler) {
return onAssembly(new FluxCancelOn<>(this, scheduler));
}那么核心便集中在FluxCancelOn的实现上:
final class FluxCancelOn<T> extends InternalFluxOperator<T, T> {
final Scheduler scheduler;
public FluxCancelOn(Flux<T> source, Scheduler scheduler) {
super(source);
this.scheduler = Objects.requireNonNull(scheduler, "scheduler");
}
@Override
public CoreSubscriber<? super T> subscribeOrReturn(CoreSubscriber<? super T> actual) {
return new CancelSubscriber<T>(actual, scheduler);
}
static final class CancelSubscriber<T>
implements InnerOperator<T, T>, Runnable {
final CoreSubscriber<? super T> actual;
final Scheduler scheduler;
Subscription s;
volatile int cancelled = 0;
static final AtomicIntegerFieldUpdater<CancelSubscriber> CANCELLED =
AtomicIntegerFieldUpdater.newUpdater(CancelSubscriber.class, "cancelled");
CancelSubscriber(CoreSubscriber<? super T> actual, Scheduler scheduler) {
this.actual = actual;
this.scheduler = scheduler;
}
@Override
public void run() {
s.cancel();
}
// 省略一大堆,都是调用对应类的对应方法
@Override
public void cancel() {
if (CANCELLED.compareAndSet(this, 0, 1)) {
try {
scheduler.schedule(this);
}
catch (RejectedExecutionException ree) {
throw Operators.onRejectedExecution(ree, actual.currentContext());
}
}
}
}
}注意:下文的前后顺序指的是代码顺序。比如map在take之前。上下游指的是运行时执行顺序,比如map的request在take的request之后执行,而map的onNext却在take的onNext之前执行。
首先前文有提subscribeOrReturn会在InternalFluxOperator的subscribe方法被调用调用,这意味着传导至上游的Subscription对象与Subscriber都是增强过的对象,会随着当前节点通过subscribe方法一直向上传播增强此节点之前的链路上的所有Subscriber对象,也会随着onSubscribe回调增强链路上的所有Subscription对象,而cancel方法就是Subscription对象的一个方法,而他是此条链路上唯一被增强的方法,cancel是由下游调用传导到上游的,此节点之前的所有cancel调用都将在都将在cancelOn(Schedulers.newParallel("cancelOn")) 设置的调度器下面执行。take在获取到足额的元素的之后会向上调用cancel。cancelOn之后的节点调用cancel时候是没有被增强的,所以在publishOn上调度,而cancelOn之后的节点之前的节点的cancel已经增强了,所以在cancelOn上被调度。所以执行日志如下:
16:42:11.141 [publishOn-2] INFO org.example.webflux.ReactorTest - subscribeOn之前, cancelOn publishOn之后---- doOnCancel
16:42:11.142 [cancelOn-3] INFO org.example.webflux.ReactorTest - subscribeOn、cancelOn之前,publishOn之后---- doOnCancel为什么我们需要在cancel阶段可以设置单独的调度器呢?这是为了回收耗时资源而设计的。
接下来我们分析subscribeOn。依然是装饰者模式增强:
public final Flux<T> subscribeOn(Scheduler scheduler, boolean requestOnSeparateThread) {
if (this instanceof Callable) {
if (this instanceof Fuseable.ScalarCallable) {
try {
@SuppressWarnings("unchecked") T value = ((Fuseable.ScalarCallable<T>) this).call();
return onAssembly(new FluxSubscribeOnValue<>(value, scheduler));
}
catch (Exception e) {
//leave FluxSubscribeOnCallable defer error
}
}
@SuppressWarnings("unchecked")
Callable<T> c = (Callable<T>)this;
return onAssembly(new FluxSubscribeOnCallable<>(c, scheduler));
}
return onAssembly(new FluxSubscribeOn<>(this, scheduler, requestOnSeparateThread));
}我们接着看FluxSubscribeOn,实际上与cancelOn是十分类似的:
final class FluxSubscribeOn<T> extends InternalFluxOperator<T, T> {
final Scheduler scheduler;
final boolean requestOnSeparateThread;
FluxSubscribeOn(
Flux<? extends T> source,
Scheduler scheduler,
boolean requestOnSeparateThread) {
super(source);
this.scheduler = Objects.requireNonNull(scheduler, "scheduler");
this.requestOnSeparateThread = requestOnSeparateThread;
}
@Override
public CoreSubscriber<? super T> subscribeOrReturn(CoreSubscriber<? super T> actual) {
Worker worker = Objects.requireNonNull(scheduler.createWorker(),
"The scheduler returned a null Function");
SubscribeOnSubscriber<T> parent = new SubscribeOnSubscriber<>(source,
actual, worker, requestOnSeparateThread);
// 对于下游进行onSubscribe回调,
actual.onSubscribe(parent);
try {
// 对于上游接着做subscribe操作
worker.schedule(parent);
}
catch (RejectedExecutionException ree) {
if (parent.s != Operators.cancelledSubscription()) {
actual.onError(Operators.onRejectedExecution(ree, parent, null, null,
actual.currentContext()));
}
}
// 注意这里返回null,这意味着InternalFluxOperator不会继续下游的subscribe
return null;
}
static final class SubscribeOnSubscriber<T> implements InnerOperator<T, T>, Runnable {
@Override
public void onSubscribe(Subscription s) {
if (Operators.setOnce(S, this, s)) {
long r = REQUESTED.getAndSet(this, 0L);
if (r != 0L) {
// 将使用调度器
requestUpstream(r, s);
}
}
}
void requestUpstream(final long n, final Subscription s) {
if (!requestOnSeparateThread || Thread.currentThread() == THREAD.get(this)) {
s.request(n);
}
else {
try {
// 使用调度器
worker.schedule(() -> s.request(n));
}
catch (RejectedExecutionException ree) {
if(!worker.isDisposed()) {
actual.currentContext());
}
}
}
}
@Override
public void request(long n) {
if (Operators.validate(n)) {
Subscription s = S.get(this);
if (s != null) {
requestUpstream(n, s);
}
else {
Operators.addCap(REQUESTED, this, n);
s = S.get(this);
if (s != null) {
long r = REQUESTED.getAndSet(this, 0L);
if (r != 0L) {
requestUpstream(r, s);
}
}
}
}
}
@Override
public void run() {
THREAD.lazySet(this, Thread.currentThread());
source.subscribe(this);
}
}
}首先我们依然看subscribeOrReturn的逻辑,依然是创建SubscribeOnSubscriber对象,不过与cancel不同的是,在此节点分为了两个部分,首先此节点自行处理了 actual.onSubscribe(parent); 此步是为了保证,后面的节点在调用request的时候见过当前节点时可以顺利转换调度器,保证此节点之前的节点全部使用新的调度器调度。我们可以在requestUpstream看到。然后此节点使用调度器 worker.schedule(parent); 向之前的节点接着执行subscribe,可以在run方法看到,这可以保证之前的节点的subscribe方法与onSubscribe方法在新的调度器上执行。总之,经过此节点的流程(注意是流程)都将切换到新的调度器上执行。 又因为onNext、onComplete、onError和cancel之类的回调通常发生在request之后,所以在没有切换调度器之前的所有调度器都是这个新的 subscribeOn 调度器。
我们可以看到SubscribeOnSubscriber只是对入口方法request和后续的subscribe进行了增强。这对我们理解调度切换是十分有帮助的,相应流程的调度切换只对相应的流程进行增强。
那么此节点之前的onSubscribe等等方法都是在新的调度之上执行的,而此节点之后的方法只有request之后的onNext之类的方法才会在新的调度之上执行,所以日志可以看到:
17:29:48.904 [main] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之后 ---- doOnSubscribe
17:29:48.905 [main] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之后---- doOnRequest 9223372036854775807
17:30:18.850 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、cancelOn之前,publishOn之后----doOnSubscribe
17:30:18.850 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn之前,cancelOn publishOn之后----doOnSubscribe
17:30:21.934 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn之前,cancelOn publishOn之后----doOnRequest 9223372036854775807
17:30:21.934 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、cancelOn之前,publishOn之后---- doOnRequest 9223372036854775807
17:30:21.934 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之前----doOnNext
17:30:21.935 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之前----doOnNext
17:30:21.935 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之前----doOnNext最后我们来看 publishOn 。分析了前面的调度,我们实际上对这个套路已经非常熟悉了,依然是装饰者增强:
final Flux<T> publishOn(Scheduler scheduler, boolean delayError, int prefetch, int lowTide) {
if (this instanceof Callable) {
if (this instanceof Fuseable.ScalarCallable) {
@SuppressWarnings("unchecked")
Fuseable.ScalarCallable<T> s = (Fuseable.ScalarCallable<T>) this;
try {
return onAssembly(new FluxSubscribeOnValue<>(s.call(), scheduler));
}
catch (Exception e) {
//leave FluxSubscribeOnCallable defer exception call
}
}
@SuppressWarnings("unchecked")
Callable<T> c = (Callable<T>)this;
return onAssembly(new FluxSubscribeOnCallable<>(c, scheduler));
}
return onAssembly(new FluxPublishOn<>(this, scheduler, delayError, prefetch, lowTide, Queues.get(prefetch)));
}重点还是 FluxPublishOn 的实现:
final class FluxPublishOn<T> extends InternalFluxOperator<T, T> implements Fuseable {
@Override
@SuppressWarnings("unchecked")
public CoreSubscriber<? super T> subscribeOrReturn(CoreSubscriber<? super T> actual) {
Worker worker = Objects.requireNonNull(scheduler.createWorker(),
"The scheduler returned a null worker");
if (actual instanceof ConditionalSubscriber) {
ConditionalSubscriber<? super T> cs = (ConditionalSubscriber<? super T>) actual;
source.subscribe(new PublishOnConditionalSubscriber<>(cs,
scheduler,
worker,
delayError,
prefetch,
lowTide,
queueSupplier));
return null; }
return new PublishOnSubscriber<>(actual,
scheduler,
worker,
delayError,
prefetch,
lowTide,
queueSupplier);
}
static final class PublishOnSubscriber<T>
implements QueueSubscription<T>, Runnable, InnerOperator<T, T> {
@Override
public void onSubscribe(Subscription s) {
if (Operators.validate(this.s, s)) {
actual.onSubscribe(this);
s.request(Operators.unboundedOrPrefetch(prefetch));
}
}
@Override
public void onNext(T t) {
if (sourceMode == ASYNC) {
trySchedule(this, null, null /* t always null */);
return; }
if (done) {
Operators.onNextDropped(t, actual.currentContext());
return; }
if (cancelled) {
Operators.onDiscard(t, actual.currentContext());
return; }
if (!queue.offer(t)) {
Operators.onDiscard(t, actual.currentContext());
error = Operators.onOperatorError(s,
Exceptions.failWithOverflow(Exceptions.BACKPRESSURE_ERROR_QUEUE_FULL),
t, actual.currentContext());
done = true;
}
trySchedule(this, null, t);
}
@Override
public void onError(Throwable t) {
if (done) {
Operators.onErrorDropped(t, actual.currentContext());
return; }
error = t;
done = true;
trySchedule(null, t, null);
}
@Override
public void onComplete() {
if (done) {
return;
}
done = true;
//WIP also guards, no competing onNext
trySchedule(null, null, null);
}
@Override
public void request(long n) {
if (Operators.validate(n)) {
Operators.addCap(REQUESTED, this, n);
//WIP also guards during request and onError is possible
trySchedule(this, null, null);
}
}
@Override
public void cancel() {
}
void trySchedule(
@Nullable Subscription subscription,
@Nullable Throwable suppressed,
@Nullable Object dataSignal) {
worker.schedule(this);
}
void runSync() {
// 调用实际的 onNext\onComplete\onError
}
void runAsync() {
// 调用实际的 onNext\onComplete\onError
}
@Override
public void run() {
if (outputFused) {
runBackfused();
}
else if (sourceMode == Fuseable.SYNC) {
runSync();
}
else {
runAsync();
}
}
}
}我们依然可以看到subscribeOrReturn返回了增强后的PublishOnSubscriber对象。此对象处理onSubscribe回调时,继续回调下游的onSubscribe方法,然后自行调用自行调用request向上游请求数据。注意,数据并不是来一个发一个,而是放到队列里面通过通过trySchedule推送到下游。我们可以看到onNext、onComplete和onError都是被增强了,上游的回调到此将使用trySchedule切换到新的调度器,继续完成向下游回调、推送工作。注意,我们可以看到request的操作是先通过cas将新的request量增加进去,然后触发调度。runAsync和runSync的逻辑有如下处理:
void runAsync() {
int missed = 1;
final Subscriber<? super T> a = actual;
final Queue<T> q = queue;
long e = produced;
for (; ; ) {
long r = requested;
while (e != r) {
boolean d = done;
T v;
}
}
}在没有complete或者error或者中断之前会一直从队列中获取元素消费。如果队列中没有数据而没有达到requested需求则会继续向上游请求新数据。在一开始,默认是从上游获取256个元素,每一批次都将向上游请求limit数量的元素。
由于调度是在调度器执行的,所以此节点下游的onNext、onComplete、onError都将在新的调度器上执行,下游的take如果onNext达量触发cancel也是在新的调度器上执行。我们还需要注意的是由于异常导致的cancel、由于数量不足导致的request都是在新的调度器上执行的。那么我们可以看到此节点之后的调用全部在新的调度上执行,此节点之前的调用常规情况下不会收到影响,综合起来我们可以看到日志如下:
// 这两条由于在所有调度器节点执行之前,所以不会受到影响,谁调用就使用谁的线程
19:05:04.221 [main] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之后 ---- doOnSubscribe
19:05:04.222 [main] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之后---- doOnRequest 9223372036854775807
// 之后设置了subscribeOn调度器,后续几乎所有流程都将在新的调度器上执行
19:05:05.459 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、cancelOn之前,publishOn之后----doOnSubscribe
19:05:05.460 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn之前,cancelOn publishOn之后----doOnSubscribe
19:05:05.460 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn之前,cancelOn publishOn之后----doOnRequest 9223372036854775807
19:05:05.460 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、cancelOn之前,publishOn之后---- doOnRequest 9223372036854775807
19:05:06.697 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之前----doOnNext
19:05:06.697 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之前----doOnNext
19:05:06.697 [subscribeOn-1] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之前----doOnNext
// map之后的所有request之后的流程都可以看到在publishOn调度器上执行
19:05:07.581 [publishOn-2] INFO org.example.webflux.ReactorTest - subscribeOn之前, cancelOn publishOn之后 ----doOnNext
19:05:07.581 [publishOn-2] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之后 ----doOnNext
// 注意subscribe也在publishOn,因为实际上是onNext回调了lambda
19:05:07.582 [publishOn-2] INFO org.example.webflux.ReactorTest - subscribeOn、publishOn、cancelOn之后---- subscribe
// 注意cancelOn之后的cancel并不会生效
19:05:07.582 [publishOn-2] INFO org.example.webflux.ReactorTest - subscribeOn之前, cancelOn publishOn之后---- doOnCancel
// take触发cancel。在cancelOn之前所以可以看到在cancelOn调度器上执行cancel
19:05:07.583 [cancelOn-3] INFO org.example.webflux.ReactorTest - subscribeOn、cancelOn之前,publishOn之后---- doOnCancel
19:05:07.583 [publishOn-2] INFO org.example.webflux.ReactorTest - subscribeOn之前, cancelOn publishOn之后 ----doOnNext
19:05:07.584 [publishOn-2] DEBUG reactor.core.publisher.Operators - onNextDropped: 2自此,我们的调度部分就已经分析完成了。可以总结一下,我们可以大致将流程分为三个阶段:握手(subscribe、onSubscribe、request)、数据传输(onNext、onComplete、onError)、取消(cancel)。
每个调度器生效的时机都不一样,增强的方法也不一样,所以影响范围也不一样。对于subscribeOn生效最早,节点后续的几乎所有流程的下游都会在此调度器上,publisherOn影响数据回调过程,此节点下游的onNext等等方法都会在此调度器之上,cancelOn的影响范围最小,只影响此节点下游的cancel过程。
最后,我们还需要分析一下调度器的覆盖,假设一个链路上多次调用subscribeOn、publisherOn、cancelOn,它们的行为会是怎么样的:
subscribeOn s1
publisherOn p1
cancelOn c1
cancelOn c2
publisherOn p2
subscribeOn s2其实我们很容易可以分析出来。我们从流程的执行顺序看,s1会覆盖掉s2的subscribe,这意味着s2到s1之间subscribe,request和onSubscribe会在s2上执行,而s1后的subscribe,request、onSubscribe、onNext,onComplete、onError、cancel都将在s1执行;而我们可以看到p1又覆盖了s1,所以实际上p1之后到p2的onNext,onComplete、onError都将在p1上执行,如果其中触发了request或者cancel,也将在p1上执行,而我们又可以看到c1覆盖了c2,这意味着p1到c1之间的cancel将在c1上执行,c1到c2之间的cancel将在c2上执行,而c2到p2之间的cancel将在p1上执行,接着p2又覆盖了p1,也就是说p2之后onNext,onComplete、onError都将在p2上执行,如果其中触发了request或者cancel,也将在p2上执行。最后s2最早被设置,s2之前subscribe,request、onSubscribe的线程是调用方线程。
reactor-netty
前文我们已经完全搞清楚了reactor的实现与调度规则。本章开头有讲,webflux是一个基于reactor-netty的web框架。reactor-netty是reactor对netty的封装,是对响应式服务的实践。
一个基于reactor-netty的响应式服务非常简单,先添加依赖:
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty-http</artifactId>
<version>1.0.11</version>
</dependency>
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty-core</artifactId>
<version>1.0.11</version>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.4.10</version>
</dependency>
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.3</version>
</dependency>代码如下:此时其实我们就已经可以看到webflux的雏形了。
package org.example.webflux;
import reactor.core.publisher.Mono;
import reactor.netty.http.server.HttpServer;
import reactor.netty.resources.LoopResources;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class NettyServer {
public static void main(String[] args) {
Map<String,String> data = new ConcurrentHashMap<>();
LoopResources loopResources = LoopResources.create("io-group", 10, true);
HttpServer.create()
.port(8888)
.route(r->{
r.get("/hello",(req,resp) -> {
String name = data.get("name");
return resp.sendString(Mono.just(name+" Hello World!"));
}).post("/hello",(req,resp)-> resp.sendString(req.receiveForm().flatMap(httpData -> {
String name = null;
try {
name = httpData.getString(StandardCharsets.UTF_8);
data.put("name",name);
return Mono.just(name + " Hello World!");
} catch (IOException e) {
throw new RuntimeException(e);
}
})));
})
.runOn(loopResources)
.bindNow()
.onDispose()
.block();
}
}本文不会大量涉及netty相关的知识,只讨论reactor是如何与netty结合起来的。想了解netty可以查看之前写的 Netty的朴素解释
和netty实现一个服务非常相似,应该说,netty本身就十分契合响应式服务。reactor的api设计风格还是相当统一的大量使用工厂模式与建造者模式。其中LoopResources可以类比为Netty的EventLoopGroup。
final class DefaultLoopResources extends AtomicLong implements LoopResources {
final String prefix;
final boolean daemon;
final int selectCount;
final int workerCount;
final AtomicReference<EventLoopGroup> serverLoops;
final AtomicReference<EventLoopGroup> clientLoops;
final AtomicReference<EventLoopGroup> serverSelectLoops;
final AtomicReference<EventLoopGroup> cacheNativeClientLoops;
final AtomicReference<EventLoopGroup> cacheNativeServerLoops;
final AtomicReference<EventLoopGroup> cacheNativeSelectLoops;
final AtomicBoolean running;
DefaultLoopResources(String prefix, int workerCount, boolean daemon) {
this(prefix, -1, workerCount, daemon);
}
}HttpServer是一个抽象类,和Mono、Flux一样提供工厂,具体create的对象是HttpServerBind的对象,注意是单例的(本质是一个模板对象):
public static HttpServer create() {
return HttpServerBind.INSTANCE;
}
final class HttpServerBind extends HttpServer {
static final HttpServerBind INSTANCE = new HttpServerBind();
final HttpServerConfig config;
static final int DEFAULT_PORT = 0;
}HttpServer在bindNow()之前也和Netty一样不会启动服务。也就是说我们要在bind之前完成我们的配置(比如端口,路由,超时,线程池之类的),这个和原生netty逻辑是一样的。而对于reactor来说,在bind之前的大部分操作实际上都是在设置HttpServerConfig:
public final class HttpServerConfig extends ServerTransportConfig<HttpServerConfig> {
boolean accessLogEnabled;
Function<AccessLogArgProvider, AccessLog> accessLog;
BiPredicate<HttpServerRequest, HttpServerResponse> compressPredicate;
ServerCookieDecoder cookieDecoder;
ServerCookieEncoder cookieEncoder;
HttpRequestDecoderSpec decoder;
HttpServerFormDecoderProvider formDecoderProvider;
BiFunction<ConnectionInfo, HttpRequest, ConnectionInfo> forwardedHeaderHandler;
Http2SettingsSpec http2Settings;
Duration idleTimeout;
BiFunction<? super Mono<Void>, ? super Connection, ? extends Mono<Void>> mapHandle;
int minCompressionSize;
HttpProtocol[] protocols;
int _protocols;
ProxyProtocolSupportType proxyProtocolSupportType;
boolean redirectHttpToHttps;
SslProvider sslProvider;
Function<String, String> uriTagValue;
static final boolean ACCESS_LOG = Boolean.parseBoolean(System.getProperty("reactor.netty.http.server.accessLogEnabled", "false"));
static final int h2 = 2;
static final int h2c = 1;
static final int h11 = 4;
static final int h11orH2 = 6;
static final int h11orH2C = 5;
static final Logger log = Loggers.getLogger(HttpServerConfig.class);
static final LoggingHandler LOGGING_HANDLER;
static final boolean SSL_DEBUG;
}
public abstract class ServerTransportConfig<CONF extends TransportConfig> extends TransportConfig {
Map<AttributeKey<?>, ?> childAttrs;
ConnectionObserver childObserver;
Map<ChannelOption<?>, ?> childOptions;
Consumer<? super CONF> doOnBind;
Consumer<? super DisposableServer> doOnBound;
Consumer<? super Connection> doOnConnection;
Consumer<? super DisposableServer> doOnUnbound;
}
public abstract class TransportConfig {
Map<AttributeKey<?>, ?> attrs;
Supplier<? extends SocketAddress> bindAddress;
ChannelGroup channelGroup;
ChannelPipelineConfigurer doOnChannelInit;
LoggingHandler loggingHandler;
LoopResources loopResources;
ChannelMetricsRecorder metricsRecorder;
ConnectionObserver observer;
Map<ChannelOption<?>, ?> options;
boolean preferNative;
static final Logger log = Loggers.getLogger(TransportConfig.class);
}此时我们已经可以看到Netty里面使用的AttributeKey、ChannelGroup和ChannelOption等等一大堆相应的设置。也可以看到http协议特异的相关设置。举个例子,我们设置的route就是被包装成了handle:
public final HttpServer route(Consumer<? super HttpServerRoutes> routesBuilder) {
Objects.requireNonNull(routesBuilder, "routeBuilder");
HttpServerRoutes routes = HttpServerRoutes.newRoutes();
routesBuilder.accept(routes);
return this.handle(routes);
}
public final HttpServer handle(BiFunction<? super HttpServerRequest, ? super HttpServerResponse, ? extends Publisher<Void>> handler) {
Objects.requireNonNull(handler, "handler");
return (HttpServer)this.childObserve(new HttpServerHandle(handler));
}
public T childObserve(ConnectionObserver observer) {
Objects.requireNonNull(observer, "observer");
T dup = (ServerTransport)this.duplicate();
ConnectionObserver current = ((ServerTransportConfig)this.configuration()).childObserver;
((ServerTransportConfig)dup.configuration()).childObserver = current == null ? observer : current.then(observer);
return dup;
}注意这不是netty的handler,这个childObserver是一个ConnectionObserver对象,它将在后续的bind过程中再次被包装成netty的handler然后才会生效。再比如runOn实际上也是设置这个config:
public T runOn(LoopResources loopResources, boolean preferNative) {
Objects.requireNonNull(loopResources, "loopResources");
T dup = duplicate();
TransportConfig c = dup.configuration();
c.loopResources = loopResources;
c.preferNative = preferNative;
return dup;
}在bind之前都是没有生效的,所以我们核心来看bindNow的过程:
public final DisposableServer bindNow(Duration timeout) {
Objects.requireNonNull(timeout, "timeout");
try {
return Objects.requireNonNull(bind().block(timeout), "aborted");
}
catch (IllegalStateException e) {
if (e.getMessage()
.contains("blocking read")) {
throw new IllegalStateException(getClass().getSimpleName() + " couldn't be started within " + timeout.toMillis() + "ms");
}
throw e;
}
}核心是这句 bind().block(timeout) , 我们注意到bind方法返回的是一个Mono,也就是一个Publisher,也就是说它在subscribe之前内部的逻辑都是不会触发的,而Mono的block方法就是创建Subscriber,并阻塞获取结果的:
public Mono<? extends DisposableServer> bind() {}
@Nullable
public T block(Duration timeout) {
BlockingMonoSubscriber<T> subscriber = new BlockingMonoSubscriber<>();
subscribe((Subscriber<T>) subscriber);
return subscriber.blockingGet(timeout.toNanos(), TimeUnit.NANOSECONDS);
}接下来的整个过程我们可以看到大量的使用到Reactor提供的响应式工具。我们先聚焦在bind的实现上:
public Mono<? extends DisposableServer> bind() {
CONF config = configuration();
Objects.requireNonNull(config.bindAddress(), "bindAddress");
Mono<? extends DisposableServer> mono = Mono.create(sink -> {
// 此处省略获取address 和 bind对象的过程,也是就是disposableServer的创建过程
// disposableServer是一个Subscriber,也是一个DisposableServer,在启动之后状态将通过onNext同步过来
// 此对象也可以用来手段关闭服务
ConnectionObserver childObs =
new ChildObserver(config.defaultChildObserver().then(config.childObserver()));
Acceptor acceptor = new Acceptor(config.childEventLoopGroup(), config.channelInitializer(childObs, null, true),
config.childOptions, config.childAttrs, isDomainSocket);
TransportConnector.bind(config, new AcceptorInitializer(acceptor), local, isDomainSocket)
.subscribe(disposableServer);
});
if (config.doOnBind() != null) {
mono = mono.doOnSubscribe(s -> config.doOnBind().accept(config));
}
return mono;
}此处省略了获取address和bind对象的过程,也是就是disposableServer的创建过程。我们可以看到返回的就是这个DisposableServer对象的Mono,再由BlockingMonoSubscriber一直暴露给用户,用户可以使用这个对象手动关闭服务。
然后创建了一个ChildObserver对象,它对我们之前提到的childObserver(也就是我们的route设置的路径处理逻辑)。
其中Acceptor的作用与netty中ServerBootstrap里面的ServerBootstrapAcceptor的作用是一样的,用以接受请求SocketChannel将其分发。创建这个对象需要一个Netty的EventLoopGroup,在本地不支持iouring、epoll、kqueue的情况下使用使用nio:
final class DefaultLoopNativeDetector {
static final DefaultLoop INSTANCE;
static final DefaultLoop NIO;
static {
NIO = new DefaultLoopNIO();
if (DefaultLoopIOUring.ioUring) {
INSTANCE = new DefaultLoopIOUring();
}
else if (DefaultLoopEpoll.epoll) {
INSTANCE = new DefaultLoopEpoll();
}
else if (DefaultLoopKQueue.kqueue) {
INSTANCE = new DefaultLoopKQueue();
}
else {
INSTANCE = NIO;
}
}
}
// 注意判断逻辑是是否有对应的类并检查是否本新系统是否支持
final class DefaultLoopIOUring implements DefaultLoop {
static final boolean ioUring;
static {
boolean ioUringCheck = false;
try {
Class.forName("io.netty.incubator.channel.uring.IOUring");
ioUringCheck = IOUring.isAvailable();
}
catch (ClassNotFoundException cnfe) {
// noop
}
ioUring = ioUringCheck;
if (log.isDebugEnabled()) {
log.debug("Default io_uring support : " + ioUring);
}
}
}那么便回到了我们熟悉的NioEventLoopGroup创建过程:
EventLoopGroup cacheNioServerLoops() {
EventLoopGroup eventLoopGroup = serverLoops.get();
if (null == eventLoopGroup) {
EventLoopGroup newEventLoopGroup = new NioEventLoopGroup(workerCount,
threadFactory(this, "nio"));
if (!serverLoops.compareAndSet(null, newEventLoopGroup)) {
//"FutureReturnValueIgnored" this is deliberate
newEventLoopGroup.shutdownGracefully(0, 0, TimeUnit.MILLISECONDS);
}
eventLoopGroup = cacheNioServerLoops();
}
return eventLoopGroup;
}由于整个过程没有使用ServerBootstrap,所以所有的配置需要自己手动配置,Acceptor对象也是因此Reactor自己创建了一个,并且不止是eventloopgroup,childChannel需要使用到的options、attrs和handler等设置都需要经由Acceptor设置,所以我们可以看到包装后的ConnectionObserver对象也就是路由处理逻辑,需要在此接着包装并传递到Acceptor,而acceptor在处理read事件之后自然和netty一样将这些设置设置进去:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
final Channel child = (Channel) msg;
// 设置处理管道
child.pipeline().addLast(childHandler);
// 设置options和attrs
TransportConnector.setChannelOptions(child, childOptions, isDomainSocket);
TransportConnector.setAttributes(child, childAttrs);
try {
// 又是熟悉的eventloopgroup注册事件
childGroup.register(child).addListener((ChannelFutureListener) future -> {
if (!future.isSuccess()) {
forceClose(child, future.cause());
}
});
}
catch (Throwable t) {
forceClose(child, t);
}
}此时SocketChannel的设置就已经全部完成了,但是ServerSocketChannel的设置还没有完成,并且地址也还没绑定,TransportConnector.bind 就是处理这个:
public static Mono<Channel> bind(TransportConfig config, ChannelInitializer<Channel> channelInitializer,
SocketAddress bindAddress, boolean isDomainSocket) {
return doInitAndRegister(config, channelInitializer, isDomainSocket)
.flatMap(channel -> {
MonoChannelPromise promise = new MonoChannelPromise(channel);
// "FutureReturnValueIgnored" this is deliberate
channel.eventLoop().execute(() -> channel.bind(bindAddress, promise.unvoid()));
return promise;
});
}注意这里返回的是一个Mono,它在外面被之前提到了disposableServer订阅了,并且这个disposableServer对象将一直向外暴露给用户使用。主要逻辑是初始化完成注册完事件之后调用底层的channel的bind将地址绑定到channel上,我们可以看到MonoChannelPromise,这既是一个Mono又是一个ChannelPromise,也就是说reactor对netty的Promise进行的适配封装。我们核心还是查看doInitAndRegister的过程:
static Mono<Channel> doInitAndRegister(
TransportConfig config,
ChannelInitializer<Channel> channelInitializer,
boolean isDomainSocket) {
EventLoopGroup elg = config.eventLoopGroup();
ChannelFactory<? extends Channel> channelFactory = config.connectionFactory(elg, isDomainSocket);
Channel channel = null;
try {
channel = channelFactory.newChannel();
if (channelInitializer instanceof ServerTransport.AcceptorInitializer) {
((ServerTransport.AcceptorInitializer) channelInitializer).acceptor.enableAutoReadTask(channel);
}
channel.pipeline().addLast(channelInitializer);
setChannelOptions(channel, config.options, isDomainSocket);
setAttributes(channel, config.attrs);
}
catch (Throwable t) {
if (channel != null) {
channel.unsafe().closeForcibly();
}
return Mono.error(t);
}
MonoChannelPromise monoChannelPromise = new MonoChannelPromise(channel);
channel.unsafe().register(elg.next(), monoChannelPromise);
Throwable cause = monoChannelPromise.cause();
if (cause != null) {
if (channel.isRegistered()) {
// "FutureReturnValueIgnored" this is deliberate
channel.close();
}
else {
channel.unsafe().closeForcibly();
}
}
return monoChannelPromise;
}首先获取获取boss eventloopgroup,然后获取ChannelFactory以创建ServerSocketChannel对象,这个对象我们我们并没有手动设置,那么它是何时被设置的呢,是由相应的DefaultLoop提供的具体类,由ServerTransportConfig提供的接口。
protected ChannelFactory<? extends Channel> connectionFactory(EventLoopGroup elg, boolean isDomainSocket) {
return () -> loopResources().onChannel(channelType(isDomainSocket), elg);
}
// LoopResources的方法
default <CHANNEL extends Channel> CHANNEL onChannel(Class<CHANNEL> channelType, EventLoopGroup group) {
DefaultLoop channelFactory =
DefaultLoopNativeDetector.INSTANCE.supportGroup(group) ?
DefaultLoopNativeDetector.INSTANCE :
DefaultLoopNativeDetector.NIO;
return channelFactory.getChannel(channelType);
}
// ServerTransportConfig的方法
@Override
protected Class<? extends Channel> channelType(boolean isDomainSocket) {
return isDomainSocket ? ServerDomainSocketChannel.class : ServerSocketChannel.class;
}
// 我们默认使用的NIO
final class DefaultLoopNIO implements DefaultLoop {
@Override
@SuppressWarnings("unchecked")
public <CHANNEL extends Channel> CHANNEL getChannel(Class<CHANNEL> channelClass) {
if (channelClass.equals(SocketChannel.class)) {
return (CHANNEL) new NioSocketChannel();
}
if (channelClass.equals(ServerSocketChannel.class)) {
return (CHANNEL) new NioServerSocketChannel();
}
if (channelClass.equals(DatagramChannel.class)) {
return (CHANNEL) new NioDatagramChannel();
}
throw new IllegalArgumentException("Unsupported channel type: " + channelClass.getSimpleName());
}
@Override
@SuppressWarnings("unchecked")
public <CHANNEL extends Channel> Class<? extends CHANNEL> getChannelClass(Class<CHANNEL> channelClass) {
if (channelClass.equals(SocketChannel.class)) {
return (Class<? extends CHANNEL>) NioSocketChannel.class;
}
if (channelClass.equals(ServerSocketChannel.class)) {
return (Class<? extends CHANNEL>) NioServerSocketChannel.class;
}
if (channelClass.equals(DatagramChannel.class)) {
return (Class<? extends CHANNEL>) NioDatagramChannel.class;
}
throw new IllegalArgumentException("Unsupported channel type: " + channelClass.getSimpleName());
}
}接着设置handler、options、attrs就和常规的netty过程一样了,最后使用MonoChannelPromise将结果给到Subscriber对象(也就是disposableServer对象),将netty的Channel注册到相应的EventLoop
MonoChannelPromise monoChannelPromise = new MonoChannelPromise(channel);
channel.unsafe().register(elg.next(), monoChannelPromise);doInitAndRegister一切完成后调用bind绑定地址。
channel.eventLoop().execute(() -> channel.bind(bindAddress, promise.unvoid()));注意,这整个过程只有在调用bindNow,里面的BlockingMonoSubscriber通过Mono的subscribe订阅之后才会真实启动。 自此,我们已经完全对接了reactor与netty的结合过程,通过MonoChannelPromise可以非常方便的在netty使用reactor。
但是我们还还有最后一点还没有搞清楚,route使用的HttpServerRequest和HttpServerResponse是编解码之后的对象,也就是说在此过程中还有编解码器被设置了。这一步在构建Acceptor中由一个 config.channelInitializer
// Acceptor acceptor = new Acceptor(config.childEventLoopGroup(), config.channelInitializer(childObs, null, true), config.childOptions, config.childAttrs, isDomainSocket);
public final ChannelInitializer<Channel> channelInitializer(ConnectionObserver connectionObserver,
@Nullable SocketAddress remoteAddress, boolean onServer) {
requireNonNull(connectionObserver, "connectionObserver");
return new TransportChannelInitializer(this, connectionObserver, remoteAddress, onServer);
}TransportChannelInitializer便是处理了这个过程,首先使用了ChannelOperations.addReactiveBridge 将 ConnectionObserver ——这个也就是我们的route处理逻辑—— 包装成netty的handler并设置进pipeline:
protected void initChannel(Channel channel) {
ChannelPipeline pipeline = channel.pipeline();
// 此处省略一大堆
ChannelOperations.addReactiveBridge(channel, config.channelOperationsProvider(), connectionObserver);
config.defaultOnChannelInit()
.then(config.doOnChannelInit)
.onChannelInit(connectionObserver, channel, remoteAddress);
pipeline.remove(this);
if (log.isDebugEnabled()) {
log.debug(format(channel, "Initialized pipeline {}"), pipeline.toString());
}
}
}
public static void addReactiveBridge(Channel ch, OnSetup opsFactory, ConnectionObserver listener) {
ch.pipeline()
.addLast(NettyPipeline.ReactiveBridge, new ChannelOperationsHandler(opsFactory, listener));
}后续在onChannelInit过程中将必要的默认handler设置进去,比如下面就就将netty的编解码器到了我们的路由处理前面:
public void onChannelInit(ConnectionObserver observer, Channel channel, @Nullable SocketAddress remoteAddress) {
boolean needRead = false;
// 省略一大堆
} else if ((this.protocols & 4) == 4) {
HttpServerConfig.configureHttp11Pipeline(channel.pipeline(), this.accessLogEnabled, this.accessLog, HttpServerConfig.compressPredicate(this.compressPredicate, this.minCompressionSize), this.cookieDecoder, this.cookieEncoder, this.decoder, this.formDecoderProvider, this.forwardedHeaderHandler, this.idleTimeout, observer, this.mapHandle, this.metricsRecorder, this.minCompressionSize, this.uriTagValue);
} else if ((this.protocols & 1) == 1) {
// 省略一大堆
if (needRead) {
channel.read();
}
}
static void configureHttp11Pipeline(ChannelPipeline p, boolean accessLogEnabled, @Nullable Function<AccessLogArgProvider, AccessLog> accessLog, @Nullable BiPredicate<HttpServerRequest, HttpServerResponse> compressPredicate, ServerCookieDecoder cookieDecoder, ServerCookieEncoder cookieEncoder, HttpRequestDecoderSpec decoder, HttpServerFormDecoderProvider formDecoderProvider, @Nullable BiFunction<ConnectionInfo, HttpRequest, ConnectionInfo> forwardedHeaderHandler, @Nullable Duration idleTimeout, ConnectionObserver listener, @Nullable BiFunction<? super Mono<Void>, ? super Connection, ? extends Mono<Void>> mapHandle, @Nullable ChannelMetricsRecorder metricsRecorder, int minCompressionSize, @Nullable Function<String, String> uriTagValue) {
// 将netty的编解码器设置进去
p.addBefore("reactor.right.reactiveBridge", "reactor.left.httpCodec", new HttpServerCodec(decoder.maxInitialLineLength(), decoder.maxHeaderSize(), decoder.maxChunkSize(), decoder.validateHeaders(), decoder.initialBufferSize(), decoder.allowDuplicateContentLengths())).addBefore("reactor.right.reactiveBridge", "reactor.left.httpTrafficHandler", new HttpTrafficHandler(compressPredicate, cookieDecoder, cookieEncoder, formDecoderProvider, forwardedHeaderHandler, idleTimeout, listener, mapHandle));
// 省略一大堆
}上面把HttpServerCodec、HttpTrafficHandler设置到了reactiveBridge前面。那么相关的handler我们已经全部设置进去了。接下来我们看一下请求处理过程,netty相关的处理过程我们在Netty的朴素解释 已经详细讲过了,本文我们主要关注reactor相关的处理过程。那么我们的请求的整个处理的起点可以从HttpServerCodec开始,首先我们可以看到HttpServerCodec是一个双工的编解码器,请求的解码交给HttpServerRequestDecoder处理了:
public HttpServerCodec(int maxInitialLineLength, int maxHeaderSize, int maxChunkSize) {
this.queue = new ArrayDeque();
this.init(new HttpServerRequestDecoder(maxInitialLineLength, maxHeaderSize, maxChunkSize), new HttpServerResponseEncoder());
}HttpServerRequestDecoder是一个ByteToMessageDecoder,继承自HttpRequestDecoder,而继承自HttpRequestDecoder又继承自HttpObjectDecoder。我们主要看其decode方法:
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {
int oldSize = out.size();
super.decode(ctx, buffer, out);
// 此处省略
}可以看到主要解码工作是交给父类HttpObjectDecoder处理的:
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {
if (this.resetRequested) {
this.resetNow();
}
int toRead;
int toRead;
AppendableCharSequence line;
switch (this.currentState) {
case SKIP_CONTROL_CHARS:
case READ_INITIAL:
this.message = this.createMessage(initialLine);
this.currentState = HttpObjectDecoder.State.READ_HEADER;
// 前后省略一大堆
case READ_HEADER:
this.currentState = nextState;
out.add(this.message);
// 前后省略一大堆
case READ_CHUNK_SIZE:
this.chunkSize = (long)toRead;
if (toRead == 0) {
this.currentState = HttpObjectDecoder.State.READ_CHUNK_FOOTER;
return; }
this.currentState = HttpObjectDecoder.State.READ_CHUNKED_CONTENT;
// 依旧省略一大堆
case READ_CHUNKED_CONTENT:
// 省略一大堆
HttpContent chunk = new DefaultHttpContent(buffer.readRetainedSlice(toRead));
this.chunkSize -= (long)toRead;
out.add(chunk);
this.currentState = HttpObjectDecoder.State.READ_CHUNK_DELIMITER;
case READ_CHUNK_DELIMITER:
// 设置下一个状态,读取数据,写入out
return;
case READ_FIXED_LENGTH_CONTENT:
// 简化逻辑:读取数据、加入out
ByteBuf content = buffer.readRetainedSlice(toRead);
out.add(new DefaultHttpContent(content));
return;
case READ_CHUNK_FOOTER:
LastHttpContent trailer = this.readTrailingHeaders(buffer);
out.add(trailer);
// 省略一大堆
case BAD_MESSAGE:
out.add(buffer.readBytes(toRead));
}
}解码过程可以大致认为是一个逐行读取然后创建各部分对象的过程,可以大致概括为将ByteBuf解码成HttpMessage对象的过程。
protected HttpMessage createMessage(String[] initialLine) throws Exception {
return new DefaultHttpRequest(HttpVersion.valueOf(initialLine[2]), HttpMethod.valueOf(initialLine[0]), initialLine[1], this.validateHeaders);
}而HttpTrafficHandler(整个是reactor提供的handler),处理的就是HttpRequest:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 上面省略一大堆
if (msg instanceof HttpRequest) {
IdleTimeoutHandler.removeIdleTimeoutHandler(ctx.pipeline());
final HttpRequest request = (HttpRequest) msg;
// 省略一大堆
HttpServerOperations ops;
try {
ops = new HttpServerOperations(Connection.from(ctx.channel()),
listener,
request,
compress,
ConnectionInfo.from(ctx.channel(),
request,
secure,
remoteAddress,
forwardedHeaderHandler),
cookieDecoder,
cookieEncoder,
formDecoderProvider,
mapHandle,
secure);
}
catch (RuntimeException e) {
sendDecodingFailures(e, msg);
return; }
ops.bind();
listener.onStateChange(ops, ConnectionObserver.State.CONFIGURED);
ctx.fireChannelRead(msg);
return;
}
}
// 下面省略一大堆
}上面可以看到核心非常简单,创建HttpServerOperations对象(记住这个对象,它很复杂),将这个对象绑定通过 ops.bind(); 到当前channel的attr,然后改变listener状态,这个listener是创建对象时候传进去的,实际是一个ConnectionObserver,也就是被HttpServerHandle包装后的route,当然,到这里你可能已经忘了这是啥,前文讲调用route有HttpServerHandle包装的过程。总之,它是我们的路由处理逻辑的封装对象:
static final class HttpServerHandle implements ConnectionObserver {
final BiFunction<? super HttpServerRequest, ? super HttpServerResponse, ? extends Publisher<Void>> handler;
HttpServerHandle(BiFunction<? super HttpServerRequest, ? super HttpServerResponse, ? extends Publisher<Void>> handler) {
this.handler = handler;
}
@Override
@SuppressWarnings("FutureReturnValueIgnored")
public void onStateChange(Connection connection, State newState) {
if (newState == HttpServerState.REQUEST_RECEIVED) {
try {
if (log.isDebugEnabled()) {
log.debug(format(connection.channel(), "Handler is being applied: {}"), handler);
}
HttpServerOperations ops = (HttpServerOperations) connection;
Mono<Void> mono = Mono.fromDirect(handler.apply(ops, ops));
if (ops.mapHandle != null) {
mono = ops.mapHandle.apply(mono, connection);
}
mono.subscribe(ops.disposeSubscriber());
}
catch (Throwable t) {
log.error(format(connection.channel(), ""), t);
//"FutureReturnValueIgnored" this is deliberate
connection.channel()
.close();
}
}
}
}可以看到它只处理了 REQUEST_RECEIVED 状态,所以此时的状态变化并没有上面作用。最后HttpTrafficHandler继续向下游fireChannelRead。最后这个请求将交给ChannelOperationsHandler处理,Handler上文有提到,就是它将我们的ConnectionObserver,也就是HttpServerHandle,也就是route,包装成了netty handler。它的处理过程如下:
final public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg == null || msg == Unpooled.EMPTY_BUFFER || msg instanceof EmptyByteBuf) {
return;
}
try {
ChannelOperations<?, ?> ops = ChannelOperations.get(ctx.channel());
if (ops != null) {
ops.onInboundNext(ctx, msg);
}
// 下面省略一大堆首先取出ChannelOperations对象,他就是之前的HttpServerOperations对象。然后调用onInboundNext处理请求:
protected void onInboundNext(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof HttpRequest) {
try {
listener().onStateChange(this, HttpServerState.REQUEST_RECEIVED);
}
// 省略一大堆
}在此我们可以看到listener状态设置为了REQUEST_RECEIVED,此时HttpServerHandle将会正常处理请求逻辑了。逻辑非常直白:
HttpServerOperations ops = (HttpServerOperations) connection;
Mono<Void> mono = Mono.fromDirect(handler.apply(ops, ops));
mono.subscribe(ops.disposeSubscriber());就是Mono使用handler(也就是我们设置的route,本质DefaultHttpServerRoutes的对象,存储了我们设置的路由请求lambda),注意,我们的route处理有两个参数HttpServerRequest和HttpServerResponse,在这里都是HttpServerOperations对象,并且我们可以看到Subscriber也是这个ops。所以我说这个对象很复杂:
class HttpServerOperations extends HttpOperations<HttpServerRequest, HttpServerResponse>
implements HttpServerRequest, HttpServerResponse {
final BiPredicate<HttpServerRequest, HttpServerResponse> compressionPredicate;
final ConnectionInfo connectionInfo;
final ServerCookieDecoder cookieDecoder;
final ServerCookieEncoder cookieEncoder;
final ServerCookies cookieHolder;
final HttpServerFormDecoderProvider formDecoderProvider;
final BiFunction<? super Mono<Void>, ? super Connection, ? extends Mono<Void>> mapHandle;
final HttpRequest nettyRequest;
final HttpResponse nettyResponse;
final String path;
final HttpHeaders responseHeaders;
final String scheme;
Function<? super String, Map<String, String>> paramsResolver;
@Override
public CoreSubscriber<Void> disposeSubscriber() {
return this;
}
}自此我们已经知道了请求的处理过程。那么我们回到最初的route代码,可以看到我们所有的路由处理都只是返回了一个Publisher,而Publisher必须要subscribe之后,逻辑才会正常执行。
// 返回值是Publisher<Void>
BiFunction<? super HttpServerRequest, ? super HttpServerResponse, ? extends Publisher<Void>> handler在我们在HttpServerHandle的onStateChange里面将Publisher转换成Mono,然后通过subscribe触发整个响应式流程的正常流动,这就是整个处理流程的起点。
Mono<Void> mono = Mono.fromDirect(handler.apply(ops, ops));
mono.subscribe(ops.disposeSubscriber());那么reactor与netty的结合就已经清楚了。
首先服务启动过程与Channel创建过程使用MonoChannelPromise将netty状态同步过来(会onNext一个DisposableServer暴露给用户,用来手动停止服务),然后通过block来subscribe触发整个流程。对于请求的处理过程,我们的处理逻辑只需要返回Publisher,框架内部会在收到请求在之后自己subscribe触发请求处理过程。
而在整个处理过程内部,实际上也是大量的使用reactor,比如我们用到的receiveForm方法,内部调用的receiveFormInternal:
final Flux<HttpData> receiveFormInternal(HttpServerFormDecoderProvider config) {
boolean isMultipart = isMultipart();
if (!Objects.equals(method(), HttpMethod.POST) || !(isFormUrlencoded() || isMultipart)) {
return Flux.error(new IllegalStateException(
"Request is not POST or does not have Content-Type " +
"with value 'application/x-www-form-urlencoded' or 'multipart/form-data'"));
}
return Flux.defer(() ->
config.newHttpPostRequestDecoder(nettyRequest, isMultipart).flatMapMany(decoder ->
receiveObject()
.concatMap(object -> {
if (!(object instanceof HttpContent)) {
return Mono.empty();
}
HttpContent httpContent = (HttpContent) object;
if (config.maxInMemorySize > -1) {
httpContent.retain();
}
return config.maxInMemorySize == -1 ?
Flux.using(
() -> decoder.offer(httpContent),
d -> Flux.fromIterable(decoder.currentHttpData(!config.streaming)),
d -> decoder.cleanCurrentHttpData(!config.streaming)) :
Flux.usingWhen(
Mono.fromCallable(() -> decoder.offer(httpContent))
.subscribeOn(config.scheduler)
.doFinally(sig -> httpContent.release()),
d -> Flux.fromIterable(decoder.currentHttpData(true)),
}, 0)
.doFinally(sig -> decoder.destroy())));
}你可以看到内部使用 .subscribeOn(config.scheduler) 做调度切换。
webflux
自此我们已经完全清楚了reactive streams、reactor和reactor-netty。而webflux就是spring基于此封装的一个响应式web框架。spring再次简化了使用,并且进行了抽象与封装,常规情况下创建代码如下:
public class WebServerTest {
public static void main(String[] args) {
NettyReactiveWebServerFactory factory = new NettyReactiveWebServerFactory();
factory.setPort(9527);
factory.addServerCustomizers(server->{
// 设置HttpServer
return server;
});
factory.addRouteProviders(httpServerRoutes ->
httpServerRoutes.get("/hello",(req,resp)->
resp.sendString(Mono.just("hello world"))
)
);
WebServer webServer = factory.getWebServer((req, resp) -> {
PathPattern pathPattern = PathPatternParser.defaultInstance.parse("/test");
if (req.getMethod() != HttpMethod.GET) {
return Mono.empty();
}
if (!pathPattern.matches(req.getPath())) {
return Mono.empty();
}
return resp.writeWith(Mono.just(resp.bufferFactory().wrap("test gogogo".getBytes())));
});
webServer.start();
}
}其实早古版本的WebServer还有tomcat、jetty和Undertow的实现,但是servlet容器的实现大多是基于同步与线程绑定,所以挺别扭的,新版本已经去除了这些实现,只保留了NettyWebServer。
我们创建WebServer(这是一个Spring提供的接口)通常是和上面一样使用对应的Factory来创建对应的对象。过程非常简单:设置服务、添加路由、获取WebServer,启动服务。注意:addServerCustomizers使用的就是Reactor提供的HttpServer对象,在此基础进行设置,同理addRouteProviders也是使用的Reactor的HttpServerRoutes和我们上面创建Reactor的服务添加路由的逻辑是一样的。
核心逻辑集中在getWebServer和webserver的start。我们首先看getWebServer:
@Override
public WebServer getWebServer(HttpHandler httpHandler) {
HttpServer httpServer = createHttpServer();
ReactorHttpHandlerAdapter handlerAdapter = new ReactorHttpHandlerAdapter(httpHandler);
NettyWebServer webServer = createNettyWebServer(httpServer, handlerAdapter, this.lifecycleTimeout,
getShutdown());
webServer.setRouteProviders(this.routeProviders);
return webServer;
}过程非常简单,创建HttpServer对象(设置LoopResources、设置绑定地址、应用之前设置的serverCustomizers)、创建适配器将spring的HttpHandler转换成reactor的类型、创建NettyWebServer对象,最后添加路由处理,返回WebServer。获取到之后就需要启动服务了:
public void start() throws WebServerException {
if (this.disposableServer == null) {
try {
this.disposableServer = startHttpServer();
}
// 省略一大堆
}
}
DisposableServer startHttpServer() {
HttpServer server = this.httpServer;
if (this.routeProviders.isEmpty()) {
server = server.handle(this.handler);
}
else {
server = server.route(this::applyRouteProviders);
}
if (this.lifecycleTimeout != null) {
return server.bindNow(this.lifecycleTimeout);
}
return server.bindNow();
}
private void applyRouteProviders(HttpServerRoutes routes) {
for (NettyRouteProvider provider : this.routeProviders) {
routes = provider.apply(routes);
}
routes.route(ALWAYS, this.handler);
}也非常简单,设置应用route,设置handler(在getWebServer传入),最后bindNow启动HttpServer。
总的来说spring主要的增强集中在请求与响应的handler的封装而不是对Server本身的封装。和spring mvc的核心是DispatcherServlet一样,spring webflux的核心是DispatcherHandler。
配置过程
前文我们已经搞清楚了webflux作为一个响应式web框架,它的底层实现是由reactor-netty提供的,webflux在此基础上做了再封装。与绝大多数spring应用一样我们可以将整个过程分为配置过程与运行过程,即如何被配置进spring容器,应用是如何被启动,请求是如何被处理的。通过前文我们已经知道了,主要关注NettyReactiveWebServerFactory和NettyWebServer,同时提了一嘴核心是DispatcherHandler。
参考Servlet设计,webflux也提供了类似filter和servlet的设计:
// 相当于filter
public interface WebFilter {
Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain);
}
// 相当于servlet
public interface WebHandler {
Mono<Void> handle(ServerWebExchange exchange);
}而DispatcherHandler就是一个WebHandler。我们这里以最初的示例作为讲解:
- WebFilter
@Component
@Slf4j
public class TestFilter implements WebFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
log.info("do TestFilter------");
return chain.filter(exchange);
}
}- Controller
@RestController
@RequestMapping("test")
public class TestController {
@PostMapping("chat")
public ResponseEntity<?> chat(@RequestBody ChatBody body){
if (body.stream) {
// 或者使用ServerSentEvent.builder(d).build()就行更加细化控制
// ServerSentEvent.builder().event().data().id().comment().build()
List<ChatRespChunkBody> list = Arrays.stream("hello world!!!".split("")).map(d -> ChatRespChunkBody.builder().chunk(d).build()).collect(Collectors.toList());
Flux<ChatRespChunkBody> elements = Flux.fromIterable(list).delayElements(Duration.ofMillis(500));
return ResponseEntity.ok()
.contentType(MediaType.TEXT_EVENT_STREAM)
.body(elements);
}else {
return ResponseEntity.ok(ChatRespBody.builder().message("hello world!!!").build());
}
}
@Data
public static class ChatBody{
private boolean stream;
}
@Data
@Builder public static class ChatRespBody{
private String message;
}
@Data
@Builder public static class ChatRespChunkBody{
private String chunk;
}
}- App
@SpringBootApplication
public class WebfluxMain {
public static void main(String[] args) {
ApplicationContext applicationContext= SpringApplication.run(WebfluxMain.class, args);
}
}注意本文不会讲解详细的容器启动过程,关于ioc过程请查看 SpringIOC的朴素解释 。关于自动配置请查看 @EnableAutoConfiguration、@ComponentScan和@Configuration
应用配置
对于此应用,spring.factories 有自动配置如下:
org.springframework.boot.autoconfigure.web.reactive.HttpHandlerAutoConfiguration,\
org.springframework.boot.autoconfigure.web.reactive.ReactiveWebServerFactoryAutoConfiguration,\
org.springframework.boot.autoconfigure.web.reactive.WebFluxAutoConfiguration,\
org.springframework.boot.autoconfigure.web.reactive.error.ErrorWebFluxAutoConfiguration,\
org.springframework.boot.autoconfigure.web.reactive.function.client.ClientHttpConnectorAutoConfiguration,\其中ReactiveWebServerFactoryAutoConfiguration如下:
@AutoConfigureOrder(Integer.MIN_VALUE)
@Configuration(
proxyBeanMethods = false
)
@ConditionalOnClass({ReactiveHttpInputMessage.class})
@ConditionalOnWebApplication(
type = Type.REACTIVE
)
@EnableConfigurationProperties({ServerProperties.class})
@Import({BeanPostProcessorsRegistrar.class, ReactiveWebServerFactoryConfiguration.EmbeddedTomcat.class, ReactiveWebServerFactoryConfiguration.EmbeddedJetty.class, ReactiveWebServerFactoryConfiguration.EmbeddedUndertow.class, ReactiveWebServerFactoryConfiguration.EmbeddedNetty.class})
public class ReactiveWebServerFactoryAutoConfiguration {
public ReactiveWebServerFactoryAutoConfiguration() {
}
@Bean
public ReactiveWebServerFactoryCustomizer reactiveWebServerFactoryCustomizer(ServerProperties serverProperties) {
return new ReactiveWebServerFactoryCustomizer(serverProperties);
}
@Bean
@ConditionalOnMissingBean @ConditionalOnProperty(
value = {"server.forward-headers-strategy"},
havingValue = "framework"
)
public ForwardedHeaderTransformer forwardedHeaderTransformer() {
return new ForwardedHeaderTransformer();
}
public static class BeanPostProcessorsRegistrar implements ImportBeanDefinitionRegistrar, BeanFactoryAware {
private ConfigurableListableBeanFactory beanFactory;
public BeanPostProcessorsRegistrar() {
}
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
if (beanFactory instanceof ConfigurableListableBeanFactory) {
this.beanFactory = (ConfigurableListableBeanFactory)beanFactory;
}
}
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
if (this.beanFactory != null) {
this.registerSyntheticBeanIfMissing(registry, "webServerFactoryCustomizerBeanPostProcessor", WebServerFactoryCustomizerBeanPostProcessor.class, WebServerFactoryCustomizerBeanPostProcessor::new);
}
}
private <T> void registerSyntheticBeanIfMissing(BeanDefinitionRegistry registry, String name, Class<T> beanClass, Supplier<T> instanceSupplier) {
if (ObjectUtils.isEmpty(this.beanFactory.getBeanNamesForType(beanClass, true, false))) {
RootBeanDefinition beanDefinition = new RootBeanDefinition(beanClass, instanceSupplier);
beanDefinition.setSynthetic(true);
registry.registerBeanDefinition(name, beanDefinition);
}
}
}
}可以注意到import了ReactiveWebServerFactoryConfiguration.EmbeddedNetty.class,并且通过ReactiveWebServerFactoryCustomizer注入容器,在后续使用中可以将ServerProperties应用上去(也就是将application.properties里面的server.port这样的端口好之类的应用应用上去):
@Override
public void customize(ConfigurableReactiveWebServerFactory factory) {
PropertyMapper map = PropertyMapper.get().alwaysApplyingWhenNonNull();
map.from(this.serverProperties::getPort).to(factory::setPort);
map.from(this.serverProperties::getAddress).to(factory::setAddress);
map.from(this.serverProperties::getSsl).to(factory::setSsl);
map.from(this.serverProperties::getCompression).to(factory::setCompression);
map.from(this.serverProperties::getHttp2).to(factory::setHttp2);
map.from(this.serverProperties.getShutdown()).to(factory::setShutdown);
}而此项功能是由下面的WebServerFactoryCustomizerBeanPostProcessor提供的:
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof WebServerFactory) {
postProcessBeforeInitialization((WebServerFactory) bean);
}
return bean;
}
@SuppressWarnings("unchecked")
private void postProcessBeforeInitialization(WebServerFactory webServerFactory) {
LambdaSafe.callbacks(WebServerFactoryCustomizer.class, getCustomizers(), webServerFactory)
.withLogger(WebServerFactoryCustomizerBeanPostProcessor.class)
.invoke((customizer) -> customizer.customize(webServerFactory));
}而引入的Netty则是将前文提到的NettyReactiveWebServerFactory注入到了容器:
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(ReactiveWebServerFactory.class)
@ConditionalOnClass({ HttpServer.class })
static class EmbeddedNetty {
@Bean
@ConditionalOnMissingBean ReactorResourceFactory reactorServerResourceFactory() {
return new ReactorResourceFactory();
}
@Bean
NettyReactiveWebServerFactory nettyReactiveWebServerFactory(ReactorResourceFactory resourceFactory,
ObjectProvider<NettyRouteProvider> routes, ObjectProvider<NettyServerCustomizer> serverCustomizers) {
NettyReactiveWebServerFactory serverFactory = new NettyReactiveWebServerFactory();
serverFactory.setResourceFactory(resourceFactory);
routes.orderedStream().forEach(serverFactory::addRouteProviders);
serverFactory.getServerCustomizers().addAll(serverCustomizers.orderedStream().collect(Collectors.toList()));
return serverFactory;
}
}接着我们来看WebFluxAutoConfiguration:
@Configuration(proxyBeanMethods = false)
@ConditionalOnWebApplication(type = ConditionalOnWebApplication.Type.REACTIVE)
@ConditionalOnClass(WebFluxConfigurer.class)
@ConditionalOnMissingBean({ WebFluxConfigurationSupport.class })
@AutoConfigureAfter({ ReactiveWebServerFactoryAutoConfiguration.class, CodecsAutoConfiguration.class,
ValidationAutoConfiguration.class })
@AutoConfigureOrder(Ordered.HIGHEST_PRECEDENCE + 10)
public class WebFluxAutoConfiguration {
@SuppressWarnings("deprecation")
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties({ org.springframework.boot.autoconfigure.web.ResourceProperties.class,
WebProperties.class, WebFluxProperties.class })
@Import({ EnableWebFluxConfiguration.class })
@Order(0)
public static class WebFluxConfig implements WebFluxConfigurer {
}
/**
* Configuration equivalent to {@code @EnableWebFlux}.
*/ @Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties(WebProperties.class)
public static class EnableWebFluxConfiguration extends DelegatingWebFluxConfiguration {
private final WebFluxProperties webFluxProperties;
private final WebProperties webProperties;
private final WebFluxRegistrations webFluxRegistrations;
public EnableWebFluxConfiguration(WebFluxProperties webFluxProperties, WebProperties webProperties,
ObjectProvider<WebFluxRegistrations> webFluxRegistrations) {
this.webFluxProperties = webFluxProperties;
this.webProperties = webProperties;
this.webFluxRegistrations = webFluxRegistrations.getIfUnique();
}
@Bean
@Override public FormattingConversionService webFluxConversionService() {
Format format = this.webFluxProperties.getFormat();
WebConversionService conversionService = new WebConversionService(new DateTimeFormatters()
.dateFormat(format.getDate()).timeFormat(format.getTime()).dateTimeFormat(format.getDateTime()));
addFormatters(conversionService);
return conversionService;
}
@Bean
@Override public Validator webFluxValidator() {
if (!ClassUtils.isPresent("javax.validation.Validator", getClass().getClassLoader())) {
return super.webFluxValidator();
}
return ValidatorAdapter.get(getApplicationContext(), getValidator());
}
@Override
protected RequestMappingHandlerAdapter createRequestMappingHandlerAdapter() {
if (this.webFluxRegistrations != null) {
RequestMappingHandlerAdapter adapter = this.webFluxRegistrations.getRequestMappingHandlerAdapter();
if (adapter != null) {
return adapter;
}
}
return super.createRequestMappingHandlerAdapter();
}
@Override
protected RequestMappingHandlerMapping createRequestMappingHandlerMapping() {
if (this.webFluxRegistrations != null) {
RequestMappingHandlerMapping mapping = this.webFluxRegistrations.getRequestMappingHandlerMapping();
if (mapping != null) {
return mapping;
}
}
return super.createRequestMappingHandlerMapping();
}
@Bean
@Override @ConditionalOnMissingBean(name = WebHttpHandlerBuilder.LOCALE_CONTEXT_RESOLVER_BEAN_NAME)
public LocaleContextResolver localeContextResolver() {
if (this.webProperties.getLocaleResolver() == WebProperties.LocaleResolver.FIXED) {
return new FixedLocaleContextResolver(this.webProperties.getLocale());
}
AcceptHeaderLocaleContextResolver localeContextResolver = new AcceptHeaderLocaleContextResolver();
localeContextResolver.setDefaultLocale(this.webProperties.getLocale());
return localeContextResolver;
}
@Bean
@ConditionalOnMissingBean(name = WebHttpHandlerBuilder.WEB_SESSION_MANAGER_BEAN_NAME)
public WebSessionManager webSessionManager() {
DefaultWebSessionManager webSessionManager = new DefaultWebSessionManager();
CookieWebSessionIdResolver webSessionIdResolver = new CookieWebSessionIdResolver();
webSessionIdResolver.addCookieInitializer((cookie) -> cookie
.sameSite(this.webFluxProperties.getSession().getCookie().getSameSite().attribute()));
webSessionManager.setSessionIdResolver(webSessionIdResolver);
return webSessionManager;
}
}
}此处最核心的部分是EnableWebFluxConfiguration,在实现逻辑上,spring webflux与springmvc是十分接近的,都是通过DelegatingWebFluxConfiguration(也就是EnableWebFluxConfiguration)将一个极其重要的扩展点WebFluxConfigurer(类比mvc的WebMvcConfigurer)注入与应用上去。而默认的WebFluxConfig就是一个WebFluxConfigurer,我们也经常通过实现该接口来扩展能力来扩展框架能力。
@Configuration(proxyBeanMethods = false)
public class DelegatingWebFluxConfiguration extends WebFluxConfigurationSupport {
private final WebFluxConfigurerComposite configurers = new WebFluxConfigurerComposite();
@Autowired(required = false)
public void setConfigurers(List<WebFluxConfigurer> configurers) {
// 收集WebFluxConfigurer保存到WebFluxConfigurerComposite,待后续使用
if (!CollectionUtils.isEmpty(configurers)) {
this.configurers.addWebFluxConfigurers(configurers);
}
}
}同时我们也可以看到,web和webflux相关的properties配置也是在此处注入待用,注意这个WebFluxRegistrations,它用来替换默认的RequestMappingHandlerMapping和RequestMappingHandlerAdapter(虽然绝大多数时候都是不需要更换,但是也是一个扩展点):
public EnableWebFluxConfiguration(WebFluxProperties webFluxProperties, WebProperties webProperties,
ObjectProvider<WebFluxRegistrations> webFluxRegistrations) {
this.webFluxProperties = webFluxProperties;
this.webProperties = webProperties;
this.webFluxRegistrations = webFluxRegistrations.getIfUnique();
}绝大多数默认配置与需要使用到的bean都是在此时被注入的,DelegatingWebFluxConfiguration继承自WebFluxConfigurationSupport,webflux需要用到的bean都是在此被注入的,并且WebFluxConfigurer也是随着相应的bean注入被调用的:
public class WebFluxConfigurationSupport implements ApplicationContextAware {
@Override
public void setApplicationContext(@Nullable ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
if (applicationContext != null) {
Assert.state(!applicationContext.containsBean("mvcContentNegotiationManager"),
"The Java/XML config for Spring MVC and Spring WebFlux cannot both be enabled, " +
"e.g. via @EnableWebMvc and @EnableWebFlux, in the same application.");
}
}
@Bean
public DispatcherHandler webHandler() {
return new DispatcherHandler();
}
@Bean
@Order(0)
public WebExceptionHandler responseStatusExceptionHandler() {
return new WebFluxResponseStatusExceptionHandler();
}
@Bean
public RequestMappingHandlerMapping requestMappingHandlerMapping(
@Qualifier("webFluxContentTypeResolver") RequestedContentTypeResolver contentTypeResolver) {
RequestMappingHandlerMapping mapping = createRequestMappingHandlerMapping();
mapping.setOrder(0);
mapping.setContentTypeResolver(contentTypeResolver);
PathMatchConfigurer configurer = getPathMatchConfigurer();
configureAbstractHandlerMapping(mapping, configurer);
Map<String, Predicate<Class<?>>> pathPrefixes = configurer.getPathPrefixes();
if (pathPrefixes != null) {
mapping.setPathPrefixes(pathPrefixes);
}
return mapping;
}
protected RequestMappingHandlerMapping createRequestMappingHandlerMapping() {
return new RequestMappingHandlerMapping();
}
@Bean
public RequestedContentTypeResolver webFluxContentTypeResolver() {
RequestedContentTypeResolverBuilder builder = new RequestedContentTypeResolverBuilder();
configureContentTypeResolver(builder);
return builder.build();
}
@Bean
public RouterFunctionMapping routerFunctionMapping(ServerCodecConfigurer serverCodecConfigurer) {
RouterFunctionMapping mapping = createRouterFunctionMapping();
mapping.setOrder(-1); // go before RequestMappingHandlerMapping
mapping.setMessageReaders(serverCodecConfigurer.getReaders());
configureAbstractHandlerMapping(mapping, getPathMatchConfigurer());
return mapping;
}
@Bean
public HandlerMapping resourceHandlerMapping(ResourceUrlProvider resourceUrlProvider) {
ResourceLoader resourceLoader = this.applicationContext;
if (resourceLoader == null) {
resourceLoader = new DefaultResourceLoader();
}
ResourceHandlerRegistry registry = new ResourceHandlerRegistry(resourceLoader);
registry.setResourceUrlProvider(resourceUrlProvider);
addResourceHandlers(registry);
AbstractHandlerMapping handlerMapping = registry.getHandlerMapping();
if (handlerMapping != null) {
configureAbstractHandlerMapping(handlerMapping, getPathMatchConfigurer());
}
else {
handlerMapping = new EmptyHandlerMapping();
}
return handlerMapping;
}
@Bean
public ResourceUrlProvider resourceUrlProvider() {
return new ResourceUrlProvider();
}
@Bean
public RequestMappingHandlerAdapter requestMappingHandlerAdapter(
@Qualifier("webFluxAdapterRegistry") ReactiveAdapterRegistry reactiveAdapterRegistry,
ServerCodecConfigurer serverCodecConfigurer,
@Qualifier("webFluxConversionService") FormattingConversionService conversionService,
@Qualifier("webFluxValidator") Validator validator) {
RequestMappingHandlerAdapter adapter = createRequestMappingHandlerAdapter();
adapter.setMessageReaders(serverCodecConfigurer.getReaders());
adapter.setWebBindingInitializer(getConfigurableWebBindingInitializer(conversionService, validator));
adapter.setReactiveAdapterRegistry(reactiveAdapterRegistry);
ArgumentResolverConfigurer configurer = new ArgumentResolverConfigurer();
configureArgumentResolvers(configurer);
adapter.setArgumentResolverConfigurer(configurer);
return adapter;
}
protected RequestMappingHandlerAdapter createRequestMappingHandlerAdapter() {
return new RequestMappingHandlerAdapter();
}
@Bean
public ServerCodecConfigurer serverCodecConfigurer() {
ServerCodecConfigurer serverCodecConfigurer = ServerCodecConfigurer.create();
configureHttpMessageCodecs(serverCodecConfigurer);
return serverCodecConfigurer;
}
@Bean
public LocaleContextResolver localeContextResolver() {
return createLocaleContextResolver();
}
@Bean
public FormattingConversionService webFluxConversionService() {
FormattingConversionService service = new DefaultFormattingConversionService();
addFormatters(service);
return service;
}
@Bean
public ReactiveAdapterRegistry webFluxAdapterRegistry() {
return new ReactiveAdapterRegistry();
}
@Bean
public Validator webFluxValidator() {
Validator validator = getValidator();
if (validator == null) {
if (ClassUtils.isPresent("javax.validation.Validator", getClass().getClassLoader())) {
Class<?> clazz;
try {
String name = "org.springframework.validation.beanvalidation.OptionalValidatorFactoryBean";
clazz = ClassUtils.forName(name, getClass().getClassLoader());
}
catch (ClassNotFoundException | LinkageError ex) {
throw new BeanInitializationException("Failed to resolve default validator class", ex);
}
validator = (Validator) BeanUtils.instantiateClass(clazz);
}
else {
validator = new NoOpValidator();
}
}
return validator;
}
@Bean
public HandlerFunctionAdapter handlerFunctionAdapter() {
return new HandlerFunctionAdapter();
}
@Bean
public SimpleHandlerAdapter simpleHandlerAdapter() {
return new SimpleHandlerAdapter();
}
@Bean
public WebSocketHandlerAdapter webFluxWebSocketHandlerAdapter() {
WebSocketHandlerAdapter adapter = new WebSocketHandlerAdapter(initWebSocketService());
// Lower the (default) priority for now, for backwards compatibility
int defaultOrder = adapter.getOrder();
adapter.setOrder(defaultOrder + 1);
return adapter;
}
private WebSocketService initWebSocketService() {
WebSocketService service = getWebSocketService();
if (service == null) {
try {
service = new HandshakeWebSocketService();
}
catch (IllegalStateException ex) {
// Don't fail, test environment perhaps
service = new NoUpgradeStrategyWebSocketService();
}
}
return service;
}
@Bean
public ResponseEntityResultHandler responseEntityResultHandler(
@Qualifier("webFluxAdapterRegistry") ReactiveAdapterRegistry reactiveAdapterRegistry,
ServerCodecConfigurer serverCodecConfigurer,
@Qualifier("webFluxContentTypeResolver") RequestedContentTypeResolver contentTypeResolver) {
return new ResponseEntityResultHandler(serverCodecConfigurer.getWriters(),
contentTypeResolver, reactiveAdapterRegistry);
}
@Bean
public ResponseBodyResultHandler responseBodyResultHandler(
@Qualifier("webFluxAdapterRegistry") ReactiveAdapterRegistry reactiveAdapterRegistry,
ServerCodecConfigurer serverCodecConfigurer,
@Qualifier("webFluxContentTypeResolver") RequestedContentTypeResolver contentTypeResolver) {
return new ResponseBodyResultHandler(serverCodecConfigurer.getWriters(),
contentTypeResolver, reactiveAdapterRegistry);
}
@Bean
public ViewResolutionResultHandler viewResolutionResultHandler(
@Qualifier("webFluxAdapterRegistry") ReactiveAdapterRegistry reactiveAdapterRegistry,
@Qualifier("webFluxContentTypeResolver") RequestedContentTypeResolver contentTypeResolver) {
ViewResolverRegistry registry = getViewResolverRegistry();
List<ViewResolver> resolvers = registry.getViewResolvers();
ViewResolutionResultHandler handler = new ViewResolutionResultHandler(
resolvers, contentTypeResolver, reactiveAdapterRegistry);
handler.setDefaultViews(registry.getDefaultViews());
handler.setOrder(registry.getOrder());
return handler;
}
@Bean
public ServerResponseResultHandler serverResponseResultHandler(ServerCodecConfigurer serverCodecConfigurer) {
List<ViewResolver> resolvers = getViewResolverRegistry().getViewResolvers();
ServerResponseResultHandler handler = new ServerResponseResultHandler();
handler.setMessageWriters(serverCodecConfigurer.getWriters());
handler.setViewResolvers(resolvers);
return handler;
}
protected final ViewResolverRegistry getViewResolverRegistry() {
if (this.viewResolverRegistry == null) {
this.viewResolverRegistry = new ViewResolverRegistry(this.applicationContext);
configureViewResolvers(this.viewResolverRegistry);
}
return this.viewResolverRegistry;
}
}我们可以看到mvc与webflux是不兼容的。可以看到核心的DispatcherHandler、RequestMappingHandlerMapping与RequestMappingHandlerAdapter都是在此被注入的。也可以看到相应的bean比如FormattingConversionService被注入时会调用相应的相应的WebFluxConfigurer的addFormatters方法。
最后我们来看HttpHandlerAutoConfiguration:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ DispatcherHandler.class, HttpHandler.class })
@ConditionalOnWebApplication(type = ConditionalOnWebApplication.Type.REACTIVE)
@ConditionalOnMissingBean(HttpHandler.class)
@AutoConfigureAfter({ WebFluxAutoConfiguration.class })
@AutoConfigureOrder(Ordered.HIGHEST_PRECEDENCE + 10)
public class HttpHandlerAutoConfiguration {
@Configuration(proxyBeanMethods = false)
public static class AnnotationConfig {
private final ApplicationContext applicationContext;
public AnnotationConfig(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
}
@Bean
public HttpHandler httpHandler(ObjectProvider<WebFluxProperties> propsProvider) {
HttpHandler httpHandler = WebHttpHandlerBuilder.applicationContext(this.applicationContext).build();
WebFluxProperties properties = propsProvider.getIfAvailable();
if (properties != null && StringUtils.hasText(properties.getBasePath())) {
Map<String, HttpHandler> handlersMap = Collections.singletonMap(properties.getBasePath(), httpHandler);
return new ContextPathCompositeHandler(handlersMap);
}
return httpHandler;
}
}
}此处最重要的是注入了HttpHandler(ContextPathCompositeHandler),前文提到webflux提供了和Servlet类似的WebFilter和WebHandler组件,而HttpHandler是spring的接口,需要ReactorHttpHandlerAdapter作为桥梁来将reactor-netty的所支持的HttpServerRoutes 给到 HttpHandler。而WebHandler又是webflux提供的接口(DispatcherHandler就是该接口的实现),那么HttpHandler又需要使用一个适配器将HttpHandler的执行给到WebHandler。
此处最重要的就是从applicationcontext中获取bean,构建出支持WebFilter、WebHandler等等组件的HttpHandler供WebServer使用,WebHttpHandlerBuilder的逻辑如下,首先从容器中获取fitler、异常处理器等等必要组件,注意这个WEB_HANDLER_BEAN_NAME就是 webHandler也就是前面提到的DispatcherHandler:
public static WebHttpHandlerBuilder applicationContext(ApplicationContext context) {
WebHttpHandlerBuilder builder = new WebHttpHandlerBuilder(
context.getBean(WEB_HANDLER_BEAN_NAME, WebHandler.class), context);
List<WebFilter> webFilters = context
.getBeanProvider(WebFilter.class)
.orderedStream()
.collect(Collectors.toList());
builder.filters(filters -> filters.addAll(webFilters));
List<WebExceptionHandler> exceptionHandlers = context
.getBeanProvider(WebExceptionHandler.class)
.orderedStream()
.collect(Collectors.toList());
builder.exceptionHandlers(handlers -> handlers.addAll(exceptionHandlers));
context.getBeanProvider(HttpHandlerDecoratorFactory.class)
.orderedStream()
.forEach(builder::httpHandlerDecorator);
try {
builder.sessionManager(
context.getBean(WEB_SESSION_MANAGER_BEAN_NAME, WebSessionManager.class));
}
catch (NoSuchBeanDefinitionException ex) {
// Fall back on default
}
try {
builder.codecConfigurer(
context.getBean(SERVER_CODEC_CONFIGURER_BEAN_NAME, ServerCodecConfigurer.class));
}
catch (NoSuchBeanDefinitionException ex) {
// Fall back on default
}
try {
builder.localeContextResolver(
context.getBean(LOCALE_CONTEXT_RESOLVER_BEAN_NAME, LocaleContextResolver.class));
}
catch (NoSuchBeanDefinitionException ex) {
// Fall back on default
}
try {
builder.forwardedHeaderTransformer(
context.getBean(FORWARDED_HEADER_TRANSFORMER_BEAN_NAME, ForwardedHeaderTransformer.class));
}
catch (NoSuchBeanDefinitionException ex) {
// Fall back on default
}
return builder;
}然后在build阶段构建对filter支持(FilteringWebHandler)与全局异常支持(ExceptionHandlingWebHandler)的WebHandler,最后基于此构建并初始化HttpWebHandlerAdapter:
public HttpHandler build() {
WebHandler decorated = new FilteringWebHandler(this.webHandler, this.filters);
decorated = new ExceptionHandlingWebHandler(decorated, this.exceptionHandlers);
HttpWebHandlerAdapter adapted = new HttpWebHandlerAdapter(decorated);
if (this.sessionManager != null) {
adapted.setSessionManager(this.sessionManager);
}
if (this.codecConfigurer != null) {
adapted.setCodecConfigurer(this.codecConfigurer);
}
if (this.localeContextResolver != null) {
adapted.setLocaleContextResolver(this.localeContextResolver);
}
if (this.forwardedHeaderTransformer != null) {
adapted.setForwardedHeaderTransformer(this.forwardedHeaderTransformer);
}
if (this.applicationContext != null) {
adapted.setApplicationContext(this.applicationContext);
}
adapted.afterPropertiesSet();
return (this.httpHandlerDecorator != null ? this.httpHandlerDecorator.apply(adapted) : adapted);
}HttpWebHandlerAdapter适配器是连接HttpHandler与WebHandler的关键:
public class HttpWebHandlerAdapter extends WebHandlerDecorator implements HttpHandler {
@Override
public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) {
if (this.forwardedHeaderTransformer != null) {
try {
request = this.forwardedHeaderTransformer.apply(request);
}
catch (Throwable ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to apply forwarded headers to " + formatRequest(request), ex);
}
response.setStatusCode(HttpStatus.BAD_REQUEST);
return response.setComplete();
}
}
ServerWebExchange exchange = createExchange(request, response);
LogFormatUtils.traceDebug(logger, traceOn ->
exchange.getLogPrefix() + formatRequest(exchange.getRequest()) +
(traceOn ? ", headers=" + formatHeaders(exchange.getRequest().getHeaders()) : ""));
return getDelegate().handle(exchange)
.doOnSuccess(aVoid -> logResponse(exchange))
.onErrorResume(ex -> handleUnresolvedError(exchange, ex))
.then(Mono.defer(response::setComplete));
}
protected ServerWebExchange createExchange(ServerHttpRequest request, ServerHttpResponse response) {
return new DefaultServerWebExchange(request, response, this.sessionManager,
getCodecConfigurer(), getLocaleContextResolver(), this.applicationContext);
}
}ServerWebExchange对象(WebFilter和WebHandler所需的参数)就是在此被创建的,具体执行时交给代理对象执行的。
应用启动
那么我们已经知道了WebServer的Factory是如何被注入到容器的,也已经知道Webflux所需的Bean比如是如何被注入容器的。接下来我们将探索服务是如何被启动被配置的的。
我们先看我们一直提到的DispatcherHandler,这原本应该在配置阶段就提的,但是这里更加合适,他在初始化阶段会获取在之前已经注入的HandlerMapping、HandlerAdapter和HandlerResultHandler,这里和DispatcherServlet差不多。最重要的是获取到了RequestMappingHandlerMapping(前面,对 @RequestMapping的支持,也就是我们使用的方式)和相应的RequestMappingHandlerAdapter(参数绑定、分发请求等等)。这些都是在WebFluxConfigurationSupport被注入的。
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
initStrategies(applicationContext);
}
protected void initStrategies(ApplicationContext context) {
Map<String, HandlerMapping> mappingBeans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
context, HandlerMapping.class, true, false);
// RequestMappingHandlerMapping(对 `@RequestMapping`的支持,也就是我们使用的方式)
// RouterFunctionMapping(对 `RouterFunction`的支持,也就是对lambda与函数式的支持)
// SimpleUrlHandlerMapping 对静态资源的支持
ArrayList<HandlerMapping> mappings = new ArrayList<>(mappingBeans.values());
AnnotationAwareOrderComparator.sort(mappings);
this.handlerMappings = Collections.unmodifiableList(mappings);
Map<String, HandlerAdapter> adapterBeans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
context, HandlerAdapter.class, true, false);
this.handlerAdapters = new ArrayList<>(adapterBeans.values());
AnnotationAwareOrderComparator.sort(this.handlerAdapters);
Map<String, HandlerResultHandler> beans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
context, HandlerResultHandler.class, true, false);
this.resultHandlers = new ArrayList<>(beans.values());
AnnotationAwareOrderComparator.sort(this.resultHandlers);
}接着我们进入应用启动,整个ApplicationContext是AnnotationConfigReactiveWebServerApplicationContext。从classpath扫描注入配置与bean这里直接跳过,我们直接看其refresh阶段做了什么:
@Override
protected void onRefresh() {
super.onRefresh();
try {
createWebServer();
}
catch (Throwable ex) {
throw new ApplicationContextException("Unable to start reactive web server", ex);
}
}
private void createWebServer() {
WebServerManager serverManager = this.serverManager;
if (serverManager == null) {
StartupStep createWebServer = this.getApplicationStartup().start("spring.boot.webserver.create");
String webServerFactoryBeanName = getWebServerFactoryBeanName();
ReactiveWebServerFactory webServerFactory = getWebServerFactory(webServerFactoryBeanName);
createWebServer.tag("factory", webServerFactory.getClass().toString());
boolean lazyInit = getBeanFactory().getBeanDefinition(webServerFactoryBeanName).isLazyInit();
this.serverManager = new WebServerManager(this, webServerFactory, this::getHttpHandler, lazyInit);
getBeanFactory().registerSingleton("webServerGracefulShutdown",
new WebServerGracefulShutdownLifecycle(this.serverManager.getWebServer()));
getBeanFactory().registerSingleton("webServerStartStop",
new WebServerStartStopLifecycle(this.serverManager));
createWebServer.end();
}
initPropertySources();
}
protected HttpHandler getHttpHandler() {
// Use bean names so that we don't consider the hierarchy
String[] beanNames = getBeanFactory().getBeanNamesForType(HttpHandler.class);
if (beanNames.length == 0) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to missing HttpHandler bean.");
}
if (beanNames.length > 1) {
throw new ApplicationContextException(
"Unable to start ReactiveWebApplicationContext due to multiple HttpHandler beans : "
+ StringUtils.arrayToCommaDelimitedString(beanNames));
}
return getBeanFactory().getBean(beanNames[0], HttpHandler.class);
}获取相应的ReactiveWebServerFactory并创建WebServerManager对象:
WebServerManager(ReactiveWebServerApplicationContext applicationContext, ReactiveWebServerFactory factory,
Supplier<HttpHandler> handlerSupplier, boolean lazyInit) {
this.applicationContext = applicationContext;
Assert.notNull(factory, "Factory must not be null");
this.handler = new DelayedInitializationHttpHandler(handlerSupplier, lazyInit);
this.webServer = factory.getWebServer(this.handler);
}
void start() {
this.handler.initializeHandler();
this.webServer.start();
this.applicationContext
.publishEvent(new ReactiveWebServerInitializedEvent(this.webServer, this.applicationContext));
}此时我们已经通过factory获取到了WebServer对象,待后续调用start启动服务,注意DelayedInitializationHttpHandler对象是在start的时候才初始化的,也就是才调用的getHttpHandler,此时才会获取到配置阶段注入的HttpHandler,也就是前文提到的ContextPathCompositeHandler,它提供了对webhandler与webfilter的支持。
上面还可以注意到serverManager与WebServerStartStopLifecycle绑定了,而此Lifecycle最重要的工作就是调用serverManager的启停:
@Override
public void start() {
this.weServerManager.start();
this.running = true;
}
@Override
public void stop() {
this.running = false;
this.weServerManager.stop();
}请求过程
前文我们已经完全清楚了webflux配置过程与相应服务是如何被启动的。接下来我们探索请求的处理过程,前文已经讲过了netty的msg转换成HttpServerRequest然后交给reactor的HttpServerRoutes处理,也讲过了spring通过ReactorHttpHandlerAdapter将reactor的HttpServerRoutes代理到HttpHandler处理请求,并且也已经知道了HttpHandler由HttpWebHandlerAdapter适配交给WebHandler处理请求的:
public class HttpWebHandlerAdapter extends WebHandlerDecorator implements HttpHandler {
@Override
public Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response) {
if (this.forwardedHeaderTransformer != null) {
try {
request = this.forwardedHeaderTransformer.apply(request);
}
catch (Throwable ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to apply forwarded headers to " + formatRequest(request), ex);
}
response.setStatusCode(HttpStatus.BAD_REQUEST);
return response.setComplete();
}
}
ServerWebExchange exchange = createExchange(request, response);
LogFormatUtils.traceDebug(logger, traceOn ->
exchange.getLogPrefix() + formatRequest(exchange.getRequest()) +
(traceOn ? ", headers=" + formatHeaders(exchange.getRequest().getHeaders()) : ""));
return getDelegate().handle(exchange)
.doOnSuccess(aVoid -> logResponse(exchange))
.onErrorResume(ex -> handleUnresolvedError(exchange, ex))
.then(Mono.defer(response::setComplete));
}
protected ServerWebExchange createExchange(ServerHttpRequest request, ServerHttpResponse response) {
return new DefaultServerWebExchange(request, response, this.sessionManager,
getCodecConfigurer(), getLocaleContextResolver(), this.applicationContext);
}
}那么接下来我们需要知道就相应的WebHandler又是如何交给对应Controller处理请求的。我们首先WebFilter是如何被应用的:
// FilteringWebHandler
public class FilteringWebHandler extends WebHandlerDecorator {
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
return this.chain.filter(exchange);
}
}
// DefaultWebFilterChain
public class DefaultWebFilterChain implements WebFilterChain {
public DefaultWebFilterChain(WebHandler handler, List<WebFilter> filters) {
Assert.notNull(handler, "WebHandler is required");
this.allFilters = Collections.unmodifiableList(filters);
this.handler = handler;
DefaultWebFilterChain chain = initChain(filters, handler);
this.currentFilter = chain.currentFilter;
this.chain = chain.chain;
}
private static DefaultWebFilterChain initChain(List<WebFilter> filters, WebHandler handler) {
DefaultWebFilterChain chain = new DefaultWebFilterChain(filters, handler, null, null);
ListIterator<? extends WebFilter> iterator = filters.listIterator(filters.size());
while (iterator.hasPrevious()) {
chain = new DefaultWebFilterChain(filters, handler, iterator.previous(), chain);
}
return chain;
}
/**
* Private constructor to represent one link in the chain. */ private DefaultWebFilterChain(List<WebFilter> allFilters, WebHandler handler,
@Nullable WebFilter currentFilter, @Nullable DefaultWebFilterChain chain) {
this.allFilters = allFilters;
this.currentFilter = currentFilter;
this.handler = handler;
this.chain = chain;
}
@Override
public Mono<Void> filter(ServerWebExchange exchange) {
return Mono.defer(() ->
this.currentFilter != null && this.chain != null ?
invokeFilter(this.currentFilter, this.chain, exchange) :
this.handler.handle(exchange));
}
private Mono<Void> invokeFilter(WebFilter current, DefaultWebFilterChain chain, ServerWebExchange exchange) {
String currentName = current.getClass().getName();
return current.filter(exchange, chain).checkpoint(currentName + " [DefaultWebFilterChain]");
}
}DefaultWebFilterChain是一个单向链表,chain字段指向前一个节点(这个节点有这个节点需要执行的filter)。构建过程由返回的Mono天然构成一个反向的链,而在执行过程中则恰好是正确的顺序:
// 这里返回的是执行前一个filter的Mono
@Component
@Slf4j
public class TestFilter implements WebFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
log.info("do TestFilter------");
return chain.filter(exchange);
}
}而在全部Filter调用完成后则执行handler,也就是反复提到的DispatcherHandler。处理如下:
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
if (this.handlerMappings == null) {
return createNotFoundError();
}
if (CorsUtils.isPreFlightRequest(exchange.getRequest())) {
return handlePreFlight(exchange);
}
return Flux.fromIterable(this.handlerMappings)
.concatMap(mapping -> mapping.getHandler(exchange))
.next()
.switchIfEmpty(createNotFoundError())
.flatMap(handler -> invokeHandler(exchange, handler))
.flatMap(result -> handleResult(exchange, result));
}
private Mono<HandlerResult> invokeHandler(ServerWebExchange exchange, Object handler) {
if (ObjectUtils.nullSafeEquals(exchange.getResponse().getStatusCode(), HttpStatus.FORBIDDEN)) {
return Mono.empty(); // CORS rejection
}
if (this.handlerAdapters != null) {
for (HandlerAdapter handlerAdapter : this.handlerAdapters) {
if (handlerAdapter.supports(handler)) {
return handlerAdapter.handle(exchange, handler);
}
}
}
return Mono.error(new IllegalStateException("No HandlerAdapter: " + handler));
}
private Mono<Void> handleResult(ServerWebExchange exchange, HandlerResult result) {
return getResultHandler(result).handleResult(exchange, result)
.checkpoint("Handler " + result.getHandler() + " [DispatcherHandler]")
.onErrorResume(ex ->
result.applyExceptionHandler(ex).flatMap(exResult -> {
String text = "Exception handler " + exResult.getHandler() +
", error=\"" + ex.getMessage() + "\" [DispatcherHandler]";
return getResultHandler(exResult).handleResult(exchange, exResult).checkpoint(text);
}));
}逻辑上非常清晰,通过HandlerMapping——此处是RequestMappingHandlerMapping——获得对应的Handler(此处是HandlerMethod对象),执行处理逻辑,然后获取合适的ResultHandler处理,通常是ResponseEntityResultHandler和ResponseBodyResultHandler。获取到对应的HandlerMethod之后将由RequestMappingHandlerAdapter执行处理逻辑:
public Mono<HandlerResult> handle(ServerWebExchange exchange, Object handler) {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Assert.state(this.methodResolver != null && this.modelInitializer != null, "Not initialized");
InitBinderBindingContext bindingContext = new InitBinderBindingContext(
getWebBindingInitializer(), this.methodResolver.getInitBinderMethods(handlerMethod));
InvocableHandlerMethod invocableMethod = this.methodResolver.getRequestMappingMethod(handlerMethod);
Function<Throwable, Mono<HandlerResult>> exceptionHandler =
ex -> handleException(ex, handlerMethod, bindingContext, exchange);
return this.modelInitializer
.initModel(handlerMethod, bindingContext, exchange)
.then(Mono.defer(() -> invocableMethod.invoke(exchange, bindingContext)))
.doOnNext(result -> result.setExceptionHandler(exceptionHandler))
.doOnNext(result -> bindingContext.saveModel())
.onErrorResume(exceptionHandler);
}参数绑定,方法执行等等工作就是在此处理的。获取到结果之之后便会交给ResoultHandler处理,HttpMessageWriter 就是在此处被使用的。
// AbstractMessageWriterResultHandler
protected Mono<Void> writeBody(@Nullable Object body, MethodParameter bodyParameter,
@Nullable MethodParameter actualParam, ServerWebExchange exchange) {
// 省略一大堆
return writer.write((Publisher) publisher, actualType, elementType,
bestMediaType, exchange.getRequest(), exchange.getResponse(),
Hints.from(Hints.LOG_PREFIX_HINT, logPrefix));
}不知你发现了没有,整个处理流程返回的都是Mono也就是一个Publisher,而它的subscribe,还需回到reactor-netty,这才是流程的起点:
HttpServerOperations ops = (HttpServerOperations) connection;
Mono<Void> mono = Mono.fromDirect(handler.apply(ops, ops));
mono.subscribe(ops.disposeSubscriber());高级特性
那么,整个webflux到此就结束了。可以说在使用和架构设计上springmvc与springwebflux是极其相似的,比如都可以通过相应Configurer提供的扩展点增强能力:
public interface WebFluxConfigurer {
default void configureContentTypeResolver(RequestedContentTypeResolverBuilder builder) {
}
default void addCorsMappings(CorsRegistry registry) {
}
default void configurePathMatching(PathMatchConfigurer configurer) {
}
default void addResourceHandlers(ResourceHandlerRegistry registry) {
}
default void configureArgumentResolvers(ArgumentResolverConfigurer configurer) {
}
default void configureHttpMessageCodecs(ServerCodecConfigurer configurer) {
}
default void addFormatters(FormatterRegistry registry) {
}
@Nullable
default Validator getValidator() {
return null;
}
@Nullable
default MessageCodesResolver getMessageCodesResolver() {
return null;
}
@Nullable
default WebSocketService getWebSocketService() {
return null;
}
default void configureViewResolvers(ViewResolverRegistry registry) {
}
}比如都是交给一个Dispatcher来分发请求。再比如使用类似Servlet一样的WebHandler,使用Filter一样的WebFilter等等。甚至多了一个WebExceptionHandler异常处理组件。
全异步 vs 线程封闭
我们可以注意到我们的请求过程全部只需要返回一个Publisher,并且我们无法使用使用类似RequestContextHolder的的获得当前请求。因为整个请求过程不再是线程封闭的,也就是说请求也不再绑定请求。这意味着基于ThreadLocal的诸多请求操作都不再能够使用。毕竟在这个过程中可以随时通过subscribeOn之类的方法切换调度,这带来了巨大的吞吐与并发性能提升,请求不再阻塞,不再需要等待请求处理完成再释放,而是在subscribe之后通过onNext之类的回调将数据给到响应即可。甚至在每个阶段,都可以切换线程处理。
这也带来了巨大的麻烦,首先是方法堆栈开销明显更大,调用链条更长,线程切换也更加频繁。也就是说在单个请求的角度,它可能要比传统的servlet接口性能更低、更加慢。
其次是基于线程绑定的技术比如ThreadLocal将失效,一个经典的例子是请求traceId记录在slf4j的MDC之中:
/**
* 链路追踪过滤器:生成 traceId,设置 MDC 并通过 Reactor Context 跨线程传播
*/
@Slf4j
@Component
@Order(1)
public class TraceFilter implements WebFilter {
public static final String TRACE_ID = "TRACE-ID";
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
String headerTraceId = exchange.getRequest().getHeaders().getFirst(TRACE_ID);
final String traceId = StringUtils.isNotBlank(headerTraceId)
? headerTraceId
: RandomStringUtils.randomAlphanumeric(12);
MDC.put(TRACE_ID, traceId);
exchange.getAttributes().put(TRACE_ID, traceId);
exchange.getResponse().getHeaders().set(TRACE_ID, traceId);
return chain.filter(exchange)
.contextWrite(ctx -> ctx.put(TRACE_ID, traceId))
.doFinally(signalType -> MDC.remove(TRACE_ID));
}
}这是存在ThreadLocal的数据,如果只是我们自己取用,那么我们可以放在context一路透传下去。但是我们需要使用MDC在我们记录日志的时候带上traceId方便我们排查问题。一个比较好的处理方式是使用Hook,开启自动上下文传播,然后将TraceId重新放到MDC。
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>context-propagation</artifactId>
</dependency>public class TraceIdThreadLocalAccessor implements ThreadLocalAccessor<String> {
@Override
public Object key() {
return TraceFilter.TRACE_ID;
}
@Override
public String getValue() {
return MDC.get(TraceFilter.TRACE_ID);
}
@Override
public void setValue(String value) {
if (value == null) {
MDC.remove(TraceFilter.TRACE_ID);
} else {
MDC.put(TraceFilter.TRACE_ID, value);
}
}
@Override
public void reset() {
MDC.remove(TraceFilter.TRACE_ID);
}
}
@Configuration
public class ApiWebConfig implements WebFluxConfigurer {
@PostConstruct
void init() {
ContextRegistry.getInstance().registerThreadLocalAccessor(new TraceIdThreadLocalAccessor());
Hooks.enableAutomaticContextPropagation();
}WebClient
如果我们想更好的接受响应式开发。那么之前基于同步的技术栈也不再适合,比如RestClient,Spring提供了WebClient作为替代:
// 自动配置
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(WebClient.class)
@AutoConfigureAfter({ CodecsAutoConfiguration.class, ClientHttpConnectorAutoConfiguration.class })
public class WebClientAutoConfiguration {
@Bean
@Scope("prototype")
@ConditionalOnMissingBean
public WebClient.Builder webClientBuilder(ObjectProvider<WebClientCustomizer> customizerProvider) {
WebClient.Builder builder = WebClient.builder();
customizerProvider.orderedStream().forEach((customizer) -> customizer.customize(builder));
return builder;
}
}
@RestController
@RequestMapping("test")
public class TestController {
@Resource
private WebClient.Builder webClientBuilder;
@GetMapping("chat")
public Flux<String> forward(){
return webClientBuilder.baseUrl("http://localhost:8080/").build().get().exchangeToFlux(resp->return resp.bodyToMono(String.class));
}
}同理,如果数据库相关的接口也可以通过r2dbc提供响应式。当然这就超出了本文范围了。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-r2dbc</artifactId>
</dependency>写在最后
AI时代以来,SSE与steamable http逐渐被大众所熟知,本次借着写token中转服务的契机探究了响应式编程,作为一个给机器、给AI、给工具使用的接口,使用低开销做到高吞吐与高并发是一个开发者避不开的问题,如果你也在构建这样一个应用,那么可以试试webflux。
说实话写此长文有点逆时代潮流,似乎探究技术原理已经不再是值得做的一件事了。但是这么多年AI用下来,我的心路历程了三个阶段,从一开始的不屑(23年的模型还是有点痴呆),到后面以为无所不能,再到现在觉得是补全人的能力,还是回归到工具属性,那么我想这一切经验总结与源码探究便还是有必要的。
参考资料: